加藤弘一
「文字コード問題早わかり」は1996年11月に「カタカナ篇」をかわきりに順次公開し、翌年3月の「ユニコード篇」で一応の完結を見ました。
その後、『電脳社会の日本語』の取材のために関係者に直接お話をうかがったり、関連資料の収集につとめたところ、多くの新事実を発掘するとともに、通説の誤りも見つかりました。本ページにも多くの誤りがありますが、直すとしたらゼロから書き直さなければならないので、内容の更新は1998年5月を最後におこなっていません。
本ページは引きつづき参考として公開をつづけますが、文字コードの歴史に興味のある方は拙著『電脳社会の日本語』(文春新書)をお読みください。(2000年 4月 7日)
東京南青山のアスキーマイクロソフト社で、アメリカ製基本ソフトの日本語化のためにシフトJISが作られていた1983年7月、ISOの第97技術委員会の総会で、2バイトの国際文字コードの制定が提案されました。ISOには200を越える技術委員会(Technical Committee)があり、第97技術委員会(TC97)は情報工学部門の国際規格を審議します。
この提案は、翌年4月、第2小委員会(Sub Committee 2 → SC2)の京都会議で承認され、10646という規格番号があたえられました。第97技術委員会第2小委員会(TC97/SC2)は文字と符号を審議する機関で、この下に、実際の開発にあたる第2作業部会(Working Group 2 → WG2)が設置されました。
例によってややこしいですが、この時期、第2小委員会(SC2)の母胎である第97技術委員会(TC97)に機構改革の動きがおこっていました。情報工学に関しては、国際電気会議(IEC)の第83技術委員会(IEC/TC83)および第46小委員会(IEC/SC46)の管轄と重なることから、1987年から ISO第97技術委員会(ISO/TC97)と IEC第83技術委員会(IEC/TC83)、IEC第46小委員会(IEC/SC46)が合併し、ISOおよび IECの第1合同技術委員会(Joint Technical Committee 1 → JTC1)として再編されたのです。
形式的には対等合併ですが、ISO第97技術委員会(ISO/TC97)が巨大組織だったことから、IEC/TC83 と IEC/SC46 を実質上吸収合併したに等しかったのです(IEC側では、現在でもこの経緯を根にもつ動きがあるそうです)。なお、この合併劇を推進した中心人物は、当時の日本情報処理学会標準化委員会副会長の高橋茂氏で、その関係からか、第1合同技術委員会(JTC 1)第1回総会は 1987年11月に東京で開かれました。
この再編にともない、2バイトの国際文字コード(後に多オクテット国際文字コード)を開発する作業グループも 1990年に名前が変わりました。
1990年以前はISO/TC97/SC2/WG2(ISO第97技術委員会第2小委員会第2作業部会)でしたが、1990年以降はISO/IEC /JTC1/SC2/WG2(ISO/IEC第1合同技術委員会第2小委員会第2作業部会)となります。まぎらわしい名称がたくさん出てきましたので、別表で確認してください。
アルファベットと数字と記号類だけなら1バイト(7bitないし8bit)で十分ですから、2バイトの国際文字コードとは漢字コードのことです。ISO 646に相当するような漢字の基本コードを作ろうという意図が主で、全世界の文字を収録した「普遍文字コード」(Universal Coded-character Set = UCS)という面はそれほど強く意識されなかったようです。
1983年時点で、漢字を収録した文字コードには日本のJIS X 0208(1978年制定、6353字)、台湾のCCCII-1(1980年制定、4808字)、中国のGB2312(1981年制定、簡体字6763字)がありました。CCCIIは、1987年の第4版までつくられたものの、廃れてしまいましたし、GB2312は中国の文字コードの基本となったものの、中国ではコンピュータがあまり動いていなかったので、十分使われるにいたってはいませんでした。2バイトの文字コードとして本格的な運用実績をつんでいたのは、日本のJIS X 0208だけという状態だったのです。
当時はインターネットといっても、アメリカ国内で大学や研究機関を相互接続する程度のものでしたから、全世界の文字を一つの普遍文字コード(UCS)に集めるというような発想は夢物語にすぎず、2バイトの国際文字コードについて積極的に発言したのは、日本とアメリカくらいだったそうです。
こういうしだいですから、第2作業部会(WG2)というワーキング・グループは出来たものの、実際の開発はさっぱり進まず、1987年になってようやく、作業部会案(Working Draft = WD)として既存のISO 2022系2バイトコードとの互換性を維持するA案と、16bitをフルに活用するまったく新規の文字コードを制定するB案の二つが、第2小委員会(SC2)のベルリン会議に提出されました。
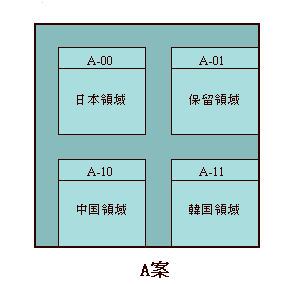
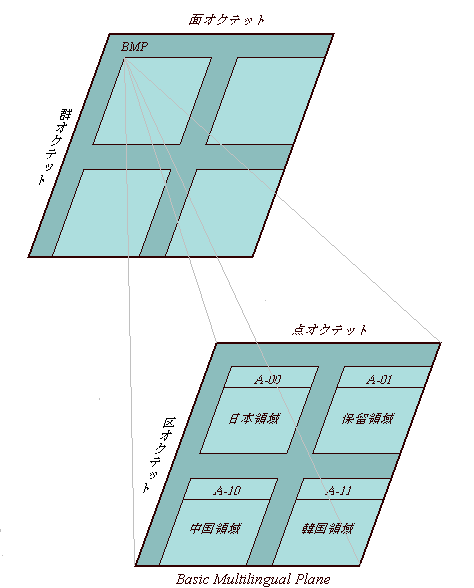
A案は、256 x 256の2バイト平面から制御文字をはずした領域に、QUADLANTと呼ばれる 94 x 94ないし 96 x 96の文字セットを4つもっています(半分以上が空きですが、世界中に厖大な蓄積のある7bitコードのデータとの共存をはかるためには、仕方がないのです)。各QUADLANTは、最初の15列(JIS風にいえば15区)分のA領域と、79ないし80列分のI領域にわかれています。
I領域の「I」とはIdeograph(絵文字=漢字)のことで、JIS X 0208、GB2312、KSC5601の漢字・ハングル部分がそっくりはめこまれ、残りの一つは保留領域とされました。A領域にはアルファベット・数字・記号・キリル文字・日本の仮名・ハングル字母(ハングルの部分品)等がはいります。
実にきれいにおさまっていますが、こんなことが出来たのは、中国のGB2312と韓国のKSC5601は日本のJIS X 0208を手本に作られていて、いずれも最初の15列(区)にアルファベット・数字・記号・キリル文字・日本語の仮名等を配置し(GBにもKSCにも仮名がはいっています)、その後に漢字を第1水準・第2水準にわけて配列していたからでした(KSC5601の場合、第1水準漢字の代わりにハングル2350字)。
なお、I領域には各国コードの漢字・ハングル部分をそのままもってきたので、後に統合されるような漢字も重複してはいっていますが、A-00からA-11までの4つのA領域のアルファベット・数字・記号・キリル文字・仮名・ハングル字母等は重複しないよう整理した上で収録されることになっていました。
| 680 x 96 | 256 x 256 | 文字 | 最大字数 |
|---|---|---|---|
| (FFhまで) | 000 | 未使用 | |
| 000-007 | 001-003 | 制御文字 | 768 |
| 008-039 | 004-015 | アルファベット等 | 3072 |
| 040-119 | 016-045 | JIS X 0208漢字部分 | 7680 |
| 120-199 | 046-075 | GB2312漢字部分 | 7680 |
| 200-295 | 076-111 | 96 x 96の保留領域 | 9216 |
| 296-391 | 112-147 | 96 x 96の保留領域 | 9216 |
| 392-487 | 148-183 | 96 x 96の保留領域 | 9216 |
| 488-583 | 184-219 | 96 x 96の保留領域 | 9216 |
| 584-679 | 220-255 | 外字領域 | 9216 |
B案には 680 x 96(JIS風にいうと、680区96点)のB-1案と、256 x 256(256区256点)のB-2案がありました。いずれも制御文字、アルファベット等の非漢字、JIS X 0208の漢字部分、GB2312の漢字部分、9216字(= 96 x 96)分の保留領域4つ、最後に外字領域という構成です。ISO 2022を無視して16bitのスペースをフルに使っていますから、A案の倍近い文字が収録可能です。
B-1案の 680 x 96は半端な構造のように見えますが、運用実績のあるJIS X 0208とGB2312は 94 x 94の配列でできていましたし、提案の年に制定されるKSC5601は 96 x 96だったので、横を 96列とすると国内コードと国際コードの相互変換が簡単になるのです。
投票では、圧倒的多数でISO 2022系の既存文字コードとの互換性を維持したA案が支持されました(B案に票を投じたのはフランスだけだったそうです)。
第2小委員会(SC2)の決定にもとづき、A案を骨子とした10646の開発がはじまりましたが、この年、中国はGB2312をおぎなうGB7589(簡体字7237字)とGB7590(簡体字7039字)という二つの文字セットをあらたに制定しましたし、日本でもJIS X 0208では文字がたりないという声が無視できなくなって、JIS X 0212(5801字)の開発に着手していました。韓国もKSC5657(2856字)という補助的な文字セットの制定に間もなくとりかかることになります。つまり、94 x 94(= 8836字)の保留領域しか空きのないA案は、採決の時点ですでにパンクしていたのです。A案の倍近い空きをもつB案でも、この4つの文字セットが加われば満杯です。
漢字を使うのは中日韓の三国だけではありません。台湾では5大メーカーが共同で制定したBig5という文字コードが事実上の標準となっていましたが、収録文字数は漢字だけで13053字もあります。CNS11643という国家標準の文字セットにいたっては、1986年から1992年にかけて5万字を越える漢字をコード化しました。16bitでは間に合うはずがなかったのです。まして全世界の文字を収録するUCSにおいてをや。
第2作業部会(WG2)では2バイト(8bit+8bit)案を見直し、4オクテット(32bit)というあらたな枠組で10646の開発を進めました。オクテットという言葉は聞きなれないかもしれません。オクテットとは符合の長さの単位で、8bitのことをいいます。8bitなら1バイトと同じではないかと思う方もいるでしょうが、「バイト」というのは、処理にあたって一まとまりとしてあつかう単位をいい、大部分のシステムでは8bit=1バイトですが、7bit=1バイトや16bit=1バイトもあるのです。B案とユニコードは、2オクテット(16bit)を1バイトとするコードです。
2バイト案では、中日韓の基本文字セットの漢字部分を集めただけですが、4オクテットとすることで、ISOに登録されているすべての文字セットをそのまま収録することが出来るようになりました。ISO 10646は単なる国際漢字コードから、普遍文字コード(Universal Coded character Set)へと、大きく性格を変えたのです。
10646のDraft Proposal(DP10646)は1989年1月に完成しました。DPは正式規格になる2段階前の試案で、現在はCommittee Draft(CD)というようです。
DP 10646は関係各国のコメントをもとに修正された後、第2小委員会(SC2)で承認され、国際規格制定の最終段階であるDraft International Standard(DIS)に進みました。DIS 10646は1989年12月に刊行されました。
DIS 10646の設計は次のような特徴をもっていました。
上記の特徴のうちで、もっとも注目すべきは、Fの「符号短縮法」でしょう。各文字は4オクテットで符号化されているとはいえ、いったんどの言語かが特定できたら、その言語面を専用するかぎり、もともと1バイトだった文字は1オクテットに、2バイトだった文字は2オクテットにもどして処理できるというのです。当時の非力なハードウェアを考えると、現実的な設計です。
見方をかえれば、これは、処理の重くなりがちなエスケープシークェンスの代わりに、32bitの言語指定符号で言語面を切り替える疑似ISO 2022方式といえるかもしれません。4オクテットで符号化しながら、マシンとネットワークの負担を軽減し、なおかつISO 2022互換への道を残したわけですから、巧妙な設計というほかはありません。
BMP(基本多言語面)という形で、A案の設計を残したのも、なかなか経済的です。ビジネス文書などだけなら、BMPを実装するだけで一応の用は足りるからです(このBMPという名称が、あとでややこしい事態を生みだすのですが)。
ところが、この規格原案は、DISの段階までいきながら、承認投票で否決されてしまいました(!)。
DIS 10646 1.0の否決の伏線は、1989年11月に開かれた第2小委員会(SC2)のアンマン会議にありました。DIS 10646の規格原案出版を目前にしていたというのに、中日韓の漢字を統合したらどうかという提案がカナダ代表からなされたのです。
この提案の背景には、米国西海岸の大手コンピュータ企業の有志が、独自に開発をすすめていたユニコードと称する内部処理用文字コード(内部コード)の存在がありました(当時のカナダ代表は、ユニコード関係者だったそうです)。
ユニコードは16bit(2オクテット)をフルに使って世界中の文字を符号化しようという規格で、ベルリン会議で退けられたB案と酷似していました。B案が中日韓の文字コードにはいっている漢字をそのまま収録することにしていたのに対し、ユニコードは三国の漢字を統合した上で収録するとしていました。
日本のJIS X 0208は6353字、中国のGB2312は6763字、韓国のKSC5601は4888字ですから、これだけで1万8千字を越えます。中国はさらに1万4千字、日本は6千字、韓国は3千字の拡張を準備していましたし、台湾にいたっては5万字を符号化していました。ところが、字形の似ている漢字を統合してしまえば、2万字程度に減らせるというのです。
漢字統合というアイデアは、ゼロックス社の Research Library Groupeが1985年から開始した漢字データベース(Unihvan Database)の作成作業から生まれたといわれています。日本のJIS X 0208と中国のGB2312を比較した結果、80%の漢字は同一だから、両者を統合することによって漢字数を半分近くに減らせるという印象をもったというのです。
このプロジェクトに参加したジョー・ベッカー、リー・コリンズらは、アップル社のマーク・デービスらと語らい、漢字統合を前提にした16bitの国際漢字コード案をあたためていました。インターネット上に議論の場が設けられると、漢字だけではなく、ISOに登録されているすべての文字を包括する普遍文字コードを作ろうという方向に話が広がっていき、Universal(普遍的)で、Uniforom(画一的)で、Unique(一意的)というモットーから、「ユニコード」という名称が生まれました。
この時点で、ユニコードが理想主義の産物であったことは確かですが、アメリカ中華思想(パックス・アメリカーナ!)の独善性がなかったとはいえません。後に設立されるユニコード技術委員会(Unicode Technical Committee=UTF)に、日本企業からただ一人参加している小林龍生氏(ジャストシステム)は、彼らの善意を認めつつも、次のように書いておられます。
先のCJKパート(統合漢字)の成り立ちについても、同様の無意識の前提が存在するように思われる。すなわち、UCS(ISO 10646)ないしUnicodeが対象とする情報分野は従来は英語で記述されるべきもので、それをそれぞれのローカルな言語に置き換える際の利便性のためにUCSないしはUnicodeが存在する、という考えである。(中略)彼らの発想の中に、たとえば現代の中国語と日本語がネットワークの上で混在するという状況は想定されていないのではないか。そう考えると、CJKをユニファイするという考え方も納得できるような気がする。(「Unicodeの概要と動向」)
オウム信者を例にあげるまでもなく、思いこみで驀進する理想主義者くらい始末の悪いものはありません。善意だからこそ、歯止めがきかないのです。
さて、理想に燃える熱血技術者のボランティア活動からはじまったユニコード構想ですが、極東市場に新製品を投入するたびにくりかえされる漢字対応作業に音を上げていたアメリカの大手コンピュータ企業の注目するところとなり、内部コードとして採用が検討されるようになりました。ヨーロッパ諸国向けなら、ISO 8859系に対応させれば終りですが、漢字を通すにはソフトウェアの根幹にかかわる手直しが必要だからです。1991年にはマイクロソフト社、アップル社、IBM社、DEC社、ノヴェル社、ヒューレット=パッカード社、サン社、AT&T社など、コンピュータ業界のトップ企業が参加して、ユニコード・コンソーシアムが設立されました。
当時、極東圏は、日本を筆頭に、台湾・韓国・香港・シンガポールの四つの小龍が目覚ましい経済成長をつづけており、コンピュータ産業にとって最重要の市場でしたが、いずれも漢字文化圏であるために、1バイトコードを前提に作られたアメリカ製OSやアプリケーションは、国ごとに異なる2バイトの文字コードに対応させなければならず、現地化(ローカリゼーション)に厖大な時間とコストがかかったのです。
もし、漢字文化圏が単一の文字コードでカバーできれば、漢字対応の改造は一回ですみます。世界共通となれば、アメリカで売るソフトウェアがそのまま全世界で売れ、現地化そのものが不要になります。
それなら既存の ISO 2022系でやればいいと思うかもしれませんが、単純な ASCIIコードを前提に作られたアメリカ製のOSやアプリケーションで、文字面を切り替える方式を実現しようとすると、基本的なところから作り直さなければならず、コストがかかりすぎました。また、当時の非力なハードウェアで、内部処理まで文字面切り替え方式でやろうとすると、重くなりすぎるという見方が一般的でした。ISO 2022系は外部コードとしてだけ使い、内部コードには単一文字面方式、それもすべての文字を同じ長さの符号で表現する固定長方式が有利とされていたのです。
ユニコードは16bitのただ一つの文字面に全世界の文字を収録することになっていました。ISO 2022系のように1バイトと2バイト、3バイトが混在することもありません(台湾で最初に作られたCCCIIコードは3バイトでした)。固定長の単一文字面方式という、アメリカ製ソフトウェアにとってはまことに都合のいい設計ですから、外部コードもユニコードで行こうという機運が生まれるのは当然のなりゆきでしょう。IBM-PCの内部コードが、ISO 8859-1として、西ヨーロッパ圏の外部コードの標準になったように、ユニコードも世界標準外部コードにしてしまおうというわけです。
漢字を統合して16bitに全世界の文字をおしこめるという主張に対し、10年以上にわたるJIS X 0208の運用実績をもっていた日本は断固として反対しました。しかし、第2小委員会の参加国のほとんどは、漢字など絵文字の一種という認識しかないアルファベット文化圏諸国でしたし、漢字文化圏の中国と韓国はコンピュータの運用経験がとぼしく、情報化が社会にあたえる影響を認識していなかったために、漢字統合という提案は好意的にむかえられました。ISO 10646を担当していた第2作業部会(WG2)は、漢字文化圏の中国、日本、韓国の三国に臨時会議を開き、漢字統合の可能性を検討するよう要請しました。
漢字統合に関する臨時会議は、翌1990年2月にソウルで開催されました。中国、日本、韓国の三国だけではなく、台湾、香港の標準化団体、さらにユニコード関係者も参加しました。 ISOの会議に、なぜ私的団体の関係者が参加できるのか、不思議に思う方がおられるかもしれません。投票権のある正式メンバーになれるのは、国・地域を代表する標準化団体(日本でいえば日本工業調査会のような)だけですが、ISOの規約には リエゾン・メンバーシップという参加資格も規定されていて、国際規格の制定に協力したいと考える団体や個人は、投票権こそないものの、私費で会議に参加することができるのです(会議は参加国持ちまわりで開かれますから、会場が毎回かわり、旅費だけでも大変です。有力なスポンサーがつかないと個人参加は不可能でしょう)。
ユニコード関係者の強引な主張に会議は紛糾しましたが、コンピュータ後進国の中国と韓国が漢字統合賛成に傾いてしまったために、日本は審議の引き延ばしをはかり、漢字統合の討議参加に、政府の承認がえられた国・地域だけが集まり、再度協議するという提案をおこないました。
この提案は、リエゾン・メンバーにすぎず、独善的な理想主義に邁進するユニコード関係者を排除するというねらいもありましたが、ユニコード関係者は、国際規格の討議の場は参加希望者すべてに門戸を開くべきだと強弁し、参加資格を勝ちとってしまいました。
漢字統合という難題を押しつけられた形の日本ですが、この問題にはどこの官庁もあまり関心がなかったことから(まさか5年足らずでインターネットが普及するとは、誰も想像しなかったのでしょう)、民間団体である情報処理学会が対応にあたり、情報規格調査会の下に漢字標準化専門委員会を時限機関として設置することになりました。普通なら、技術・文化・法制と多方面に影響のおよぶ大問題だけに、どの省庁が担当するかでもめにもめ、2年や3年は身動きがとれないところでしょうが、なにが幸いするかわからないものです。
漢字標準化専門委員会では、漢字統合に反対する声が強かったそうですが、中国と韓国がユニコード関係者に折伏されていたこと、ユニコードは世界的なコンピュータ企業が採用をちらつかせているので、ISOの規格にならなかったとしても、事実上の世界標準として登場してくるおそれがあることを考慮し、漢字統合の議論に参加することを決め、工業技術院も了承しました。
漢字統合を検討する特別会議は、1991年6月に東京で開かれることになりましたが、その直前、DIS 10646 1.0の投票結果が判明しました。否決でした。理想に燃えるユニコード関係者が、第2小委員会(SC2)参加国に対し執拗な説得工作をつづけた結果といわれています。しかも、正規の会議も開かず、主査とエディタなど一部の委員の話し合いだけで、ISO 10646プロジェクトを Committee Draftの段階に差しもどすことなく、Unicode 1.0とDIS 10646 1.0を折衷した修正案をつくることまで決まってしまいました(この決定に参加した10646のエディタは日本人でしたが、DEC社の日本法人の社員だったために、ユニコードを推進するDEC本社の意向に迎合する行動をとったと言われています)。
上部機関で Unicodeの採用が既定方針化したために、東京で開かれた統合漢字の検討会は、日本の意図したものとはまったく別の性格のものに変質してしまいました。Unicodeは漢字統合を前提にしていますから、もはや漢字統合の可否は論ずるまでもなく、Unicodeの漢字パートをいかに改良するかという実務作業の場にすりかわってしまったのです。これがCJK-JRGと略称される中日韓共同研究会(China, Japan, Korea-Joint Research Groupe)の沿革です(ややこしいですが、現在は絵文字連絡会(Ideograph Rapporteur Groupe=IRG)という名称に変わっています)。
後の話になりますが、1996年4月に、香港でアジア地域としては初のユニコード・コンファレンスが開かれ、ジャストシステム(ユニコード・コンソーシアムに日本から正式参加している唯一のメンバー企業です)と関係の深い紀田順一郎氏が基調講演をおこないました。紀田氏が日本のルビを紹介したところ、善意あふれる技術者たちは無邪気に大喜びし、会議の間中、ルビ、ルビと騒ぎまくったということです(その後、ルビは W3Cの議題にとりあげられ、RubyとしてHTMLにはいる可能性が出てきました)。
Unicode 1.0の漢字パートは、ルビの存在すら知らなかい、理想に燃えるアメリカの技術者が、JIS X 0208をもとに、アメリカ企業各社の漢字表を切り貼りして作ったお粗末な代物で、漢字国民からみると、フォントも各国の字形が混在するという異様な状態だったそうです。結局、漢字表とフォントは中国が用意したHCS-A表を採用し、漢字統合の規準は日本がつくることでまとまりました。
日本は各国の既存漢字コードとの互換性を維持するために、規準からいえば統合すべき漢字でも、元(ソース)の規格で別字とされている漢字は統合しないという原規格分離漢字規則を提案し、採用されました。このルールがないと、「既存漢字コード→CJK統合漢字」の変換はできても、逆の「CJK統合漢字→既存漢字コード」変換は不可能になってしまうのですが、その必要を切実に感じていたのは、JIS X 0208の10年以上にわたる運用実績のあった日本だけのようでした。
怪我の功名というべきかもしれませんんが、原規格分離漢字規則のおかげで、「![]() 」(いわゆる梯子高)がCJK統合漢字にはいりました。統合規準からいうと、「
」(いわゆる梯子高)がCJK統合漢字にはいりました。統合規準からいうと、「![]() 」と「高」は統合すべきなのですが、台湾のCNSコードに「
」と「高」は統合すべきなのですが、台湾のCNSコードに「![]() 」と「高」の両方がはいっているので、統合されずにすんだのです。
」と「高」の両方がはいっているので、統合されずにすんだのです。
文字コードを担当する第2小委員会の幹部は、1991年中に DIS 10646の修正版を完成させる意向でしたから、7月の東京会議の後、中日韓共同研究会(CJK-JRG)は大車輪で漢字パートの作り直しをおこない、参加国の標準文字コードにはいっている5万4千字余の漢字を、Unicode 1.0の設定した枠組に従って、2万902字に圧縮しました。
ユニコード側は、参加国の標準文字コードにははいっていないが、日本IBMの文字コードにシステム外字としてはいっている32字の漢字(JIS表外字)をCJK統合漢字セットにいれるように要求してきましたが、日本代表は枠が限られているのに、一企業の社内規格の文字を優先して入れることはできないと拒絶し、中日韓共同研究会(CJK-JRG)のレベルでは排除することに成功しました。
しかし、ユニコード側は有力なスポンサーであるIBMの意向をうけたのか、この32字に固執し、ついにISO 10646 1.2の審議の段階で、Restricted領域のCJK互換漢字に、カナダの提案という形で押しこむことに成功しました。国内規格に漢字をいれてもいないカナダが、JIS表外字の心配までしてくれるとは親切な話ですが、実は、この時のカナダ代表は、理想に燃えるユニコード関係者だったのです。
NEC固有文字や富士通固有文字をさしおいて、IBM固有文字だけが優遇されているのは、こういう経緯からだったのです。
Unicode 1.0では、日本のJIS X 0208の配列順にならっていましたが、中国の主張で康煕字典の部首順を基本とし、康煕字典にない漢字については日本の諸橋大漢和、そこにもなかったら中国の現代漢語辞典、韓国の大辞源にしたがうことが決まりました。結果として、既存文字コードのどれとも異なる配列になったわけですが、統合漢字などという偉大なる事業を強行する以上、仕方がないでしょう。
最後まで決着のつかなかった字形は、中国簡体字、台湾繁体字、日本漢字、韓国漢字を4欄併記し、各国の文字が混在するテキストでは、フォント切り換え方式で対応するという妥協案でおちつきました。たった4ヶ月という驚異的短期間で、長い歴史をもち、厖大な人口を擁する漢字文化圏の将来を決定する統合漢字案をまとめあげたのですから、作業に献身したみなさんのご苦労には本当に頭がさがります。
こうして出来たのがCJK統合漢字第1版ですが、多数の誤りがあったので、92年3月に最終修正をおこなって第2版とし、第2作業部会(WG2)に提出しました。
これがISO 10646-1のCJK統合漢字集合で、後にUnicodeにもとりいれられました。よく、ユニコードの漢字パートは、漢字文化に無知なアメリカ人が作ったから出鱈目なのだと批判する人がいますが、実際はそうではありません。CJK統合漢字に対するユニコードの貢献は、2万字程度に統合するという全体の枠組を決定したことだけで、その枠組にあわせて中味をつくったのは中国を中心とする漢字文化圏諸国の技術者でした。もしUnicode 1.0が2万字ではなく、3万字の枠を漢字に用意していたら、CJK統合漢字が現在のようなものになったかどうかはわかりませんが、それはともかくとして、ユニコード構想を理想に燃えて推進したシリコンバレーの技術者グループには、CJK統合漢字をつくりあげる能力ははじめからなかったということは確認しておいた方がいいでしょう。それなのに、16bitのバベルの塔を築こうとしたのですから、彼らの向こう見ずな理想主義には感服します。
本来ならCommittee Draftの段階からやり直すべきだったのですが(日本は国際投票の際、そう主張することになります)、否決されたDIS 10646 1.0と Unicode 1.0を折衷して、1991年中にDIS(国際規格原案)を修正するという第2小委員会幹部の決めた方針は、漢字を統合しさえすれば、16bitでどうにかなるという、参加各国に対するユニコード側の強力な説得工作によって、暗黙の支持があたえられました。正式の手続きを踏んで承認された DISと、一部私企業の団体にすぎないユニコード・コンソーシアムの一私案が同格にあつかわれる異常さも、問題になりませんでした。
DIS 10646 1.2は1992年1月に刊行され、5月に国際投票がおこなわれることになりました。よく木に竹をついだようなと言いますが、4オクテット(32bit)のDIS 10646 1.0と 2オクテット(16bit)のUnicode 1.0という、まったく構造の異なる文字コードを、どう折衷したのでしょうか?
DIS 10646 1.2は、4オクテットのUCS4と2オクテットのUCS2という2本立てにすることで、この難題に決着をつけました。
ここで、DIS 10646 1.0とDIS 10646 1.2の共通点と相違点を列挙してみましょう。
UCS4が規定されているといっても、実際のところは、UCS2(Unicode)のコードの頭に"0000h"をつければ、UCS4のコードになるという馬鹿みたいな話です。なんのことはありません、実装されるかどうかもわからないUCS4という規格を設けたのは、DIS 10646 1.0の修正という格好をつけるためだけのもので、DIS 10646 1.2は Unicodeそのものです。木に竹を接ぐのではなく、竹に「木」という名札を貼りつけただけだったのです(実際、制定後、5年もたつというのに、UCS4を実装した例は聞きません)。
もう一つ、問題なのは、言語指定の仕組を文字コードレベルから排除してしまったことです。ISO 2022や DIS 10646 1.0では、コードを見るだけで、それがどこの国の文字かを識別することができます。それはアルファベットの「a」が、英語領域、フランス語領域、ドイツ語領域等々に重複して登録してあるからなのですが、そんなことをしていたら16bit単一平面に全世界の文字を詰めこむことはできません。言語指定などは必要なく、それよりも16bit単一平面におさめる方がメリットがある、というのが当時の Unicodeの考え方だったのです。
DIS 10646 1.2に対する第2小委員会参加国からのコメントは異常な数にのぼり、1週間の会期では審議しきれなかったといいます。その大部分は統合漢字以外の記号類に関するものでした。DIS 10646 1.2の元になった Unicodeは、ユニコード・コンソーシアム参加各社の文字表を寄せ集めて作ったという経緯があるので、得体のしれない記号がいろいろまぎれこんでいたのです。

ピースマークはポピュラーだからいいとしても、「雪だるま」、「海賊の髑髏」、「下向きの鉛筆」、「水平の鉛筆」、「上向きの鉛筆」、「黒いペン先」、「白いペン先」といった絵文字がゴチャゴチャにひしめいています。規格票に例示された雪だるまは山高帽をかぶっていて、いかにもアメリカ風ですが、バケツをかぶっている雪だるまはどうなのか、何もかぶらない雪だるまでも規格適合になるのか、そもそも雪だるまの包摂規準はなになのか、ぜひ知りたいところです。
丸付き数字は 1~20までが白抜き・黒抜きの両方ではいり、それとは別に、1~10の丸付き数字(サンセリフ体)もはいっています。10進法文化の日本人の感覚では、20までなんて中途半端に思えますが、ヨーロッパでは 201進法の文化が生きていますから、どこかの会社のヨーロッパ版文字コードに 1~20までの丸付き数字が入っていたということのようです。
ところで、下の二つの図形がなにを意味するか、おわかりになりますか?

正解は「電光」と「雷電」です。気象学専攻の方のご教示によると、「国際的に使われる天気図の記号」だそうです。稲光だけの時は左、雷鳴もともなう時は右を使うのだそうです。国際的に認知された天気図記号がはいっているのは結構なのですが、正式の天気図記号はこの二つだけで、雪や雨の記号は見あたりません。雪の記号は、先に示した雪だるまですませということなのでしょうか。DIS 10646 1.2のもとになった Unicodeは協賛各社の文字コード表を寄せ集めて作ったので、この手の御都合主義がたくさんあります。
DIS 10646 1.2に対するコメントが異常に多かったのは、収録文字数の上限が決まっているにもかかわらず、わけのわからない記号がごろごろしていたためのようですが、必要な国には必要なのですから、しょうがないですね。
日本は Committee Draft段階に差し戻すよう抵抗しましたが、20対4の大差で DIS 10646 1.2は承認され、翌1993年、ISO 10646-1として国際規格になりました。規格番号の最後についた「-1」は、Latin1が「ISO 8859-1」なのと同じで、ISO 10646のパート1(第1面)という意味です。将来、パート2、パート3ができるかもしれないという含みは残しているものの、16bit固定長単一文字面で、全世界のすべての文字をまかなうというのが Unicodeの売りですから、この時点ではISO 10646もパート2、パート3が必要になるという事態は想定していませんでした(言語面を切り替える方法は、現在にいたるも決まっていません)。「-1」という尻尾は、ISO 10646の怪しげな出生の秘密を物語っていると言えましょう。
ここでごく簡単に BMP(=Unicode)の構造を見ておきます。
| 区 | 領域 | 種類 | 最大字数 |
|---|---|---|---|
| 00h-4Dh | Alphabet | 制御文字、基本ラテン、ギリシャ文字、 キリル文字、数字、記号、ハングル等 |
19968 |
| 4Eh-9Fh | Ideograph | CJK統合漢字 | 20992 |
| A0h-DFh | Open | 将来の拡張のために保留 | 16384 |
| E0h-FFh | Restricted | 外字、アラビア文字、CJK互換漢字等 | 8192 |
上記のうち、実装を義務づけられているのは基本ラテンだけで、他の文字はベンダーの判断にまかされています。ISO 10646-1制定後、UnicodeはISOとの整合をとるために、ver1.1に改訂されました。
256 x 256の約6万5千字のうち、3万4千字分が割り当てられています。まるごと保留されているOpen領域以外にも、あちこちに空きがありますが、外字に6400字分をとってあるので、拡張可能な文字は2万字程度といわれています。
ISOには、その後、文字の追加要求があいつぎ、約2万字の空きをめぐって、争奪戦がはじまりました。ISO 10646-1制定後に出てきた文字追加要求を、以下にざっと書きだしてみましょう。
これだけで、空き領域はすでにパンクしています。16bitのバベルの塔は、わずか数年にして倒壊したのです(爆笑)。
ユニコード・コンソーシアムは 1996年5月に Unicode 2.0を刊行しますが、約4千字の拡張をおこなうとともに、固定長単一文字面方式を放棄し、サロゲートペアという特殊文字を 2Kbytes分(2056字分)予約しました(D800-DFFF)。
サロゲートペアの「サロゲート」とは「代理」とか「代わり」という意味です。最近、話題の「代理母」(他人の受精卵に子宮を貸す女性)は「サロゲート・マザー」と言います。サロゲートペアは二文字で一文字の代わりをするのです。まあ、半人前文字ということですね。
サロゲートペアの 2056字は、上位バイト用1028字と下位バイト用1028字にわかれ、上位バイト+下位バイトで一文字をあらわします。つまり、1024x1024で 1048576字種が増えますが、サロゲートペア用に 2056字を予約しましたから、差し引き 1046520字の拡張ということになります(収録可能文字種数は 1112064字種)。ユニコードは16bit固定長が最大の売りでしたが、サロゲートペアの導入によって、16bit符号と32bit符号の混在する不定長コードになってしまったのです。
サロゲートペアの影響はこれにとどまりません。ユニコード・コンソーシアムは、当面、UnicodeとISO 10646の互換性維持を声明していますが(可決直前だった DIS 10646 1.0に、横槍をいれてつぶしたのですから、当然ですね)、ISO 10646には、名目だけとはいえ、32bitの UCS4がありますから、サロゲートペアによる文字拡張方式を採用する可能性はほとんどないでしょう(そんなことをしたら、UCS4とは別の32bitコードが出来てしまいます)。UCS2がどのような文字面切り替え方式を採用するかはわかりませんが(UCS2を見限り、名目的存在だったUCS4を中心にするという案が有力なようです)、サロゲートペア導入は、ISO 10646と Unicodeの将来の乖離をも予約したといっていいでしょう。
乖離を見越したのかどうかはわかりませんが、Unicode 1.1では、ISO 10646-1の採用したCJK統合漢字をそのままとりいれ、中国、台湾、日本、韓国の字形を4欄併記していたのに対し、Unicode 2.0では、例示字形は一つしかありません(どんな根拠で決めたのかは不明ですが、中国の字形が多いようです)。ISO 10646-1は、次の改訂で、先の4欄に、ベトナムとシンガポールの字形がくわわり、6欄併記になるといわれていますから、すでに乖離ははじまっているわけです。
さて、Unicodeの欠陥を浮かび上がらせる決定が、もう一つくだされようとしています。1997年7月に公開されたHTML4の仕様原案に、言語指定タグが盛りこまれたことです。
言語指定タグというのは、
<P LANG="en">English</P>というものです。インターネットがこれだけ普及した現在、言語指定は、各言語独自の字形や、禁則処理のみならず、自動翻訳の面からも、いよいよ必要性が高まっています。Unicedeおよび ISO 10646では、16bitに世界中の文字を押しこめようという妄想から、文字コードレベルにおける言語指定を排除してしまいましたが、どこかのレベルで指定しなければならないわけで、HTMLが尻ぬぐいするのもやむをえないでしょう。ただ、ワープロでも自由に改変できる HTMLのタグによる言語指定では、文字コードレベルの言語指定とは比較にならないくらい信頼性が低いのです。
<P LANG="fr">le francais</P>
<P LANG="ja">日本語</P>
<P LANG="zh">中国語</P>
Unicodeのめざした国際化とはなんだったのでしょうか? ユーザーがさまざまな言語をあつかえるようにする使用者側の国際化ではなく、メーカーがさまざまな国に最小のコストで製品を輸出できるようにする供給者側の国際化だったのではないか、という気がしてなりません。16bit平面がすぐにパンクし、言語指定も必要になるとわかっていたら、Unicodeに夢をかけた善意の技術者たちは、あんなごり押しをあえてしたかどうか……。ぜひ聞いてみたいところです。
ISO規格はすみやかに国内規格化するという取り決めにしたがい、1995年、ISO 10646-1はJIS X 0221としてJIS規格になりました。
JIS X 0221の制定と前後して、文字コードをめぐる重要な動きが日本でありました。アメリカMicrosoft社の日本法人であるマイクロソフト株式会社(MSKK)に事務局をおく Windows NT漢字処理技術協議会という業界団体が発足したのです。
Windows NT漢字処理技術協議会は、MSKKが中心という形をとっていますが、実際はパソコンのシステムを地方自治体に売りこもうと考えたいくつかの会社が、音頭をとってつくったということです。
パソコンを区役所、市役所、村役場などに導入する上で、まず問題となるのは、人名を表記する漢字がたりないということです。人名漢字には、大きな辞典でなければ載っていないような珍しい漢字もありますが、それ以上に、人名異体字と呼ばれる字形のバリエーションが厖大に存在します。「![]() 」や「
」や「![]() 」は有名ですが、「渡邊」の「邊」には、一説には、35の異体字があるといわれています。戸籍謄本や住民票を発行するには、原簿にある通りの字形を再現しなければなりませんから、大変です。
」は有名ですが、「渡邊」の「邊」には、一説には、35の異体字があるといわれています。戸籍謄本や住民票を発行するには、原簿にある通りの字形を再現しなければなりませんから、大変です。
行政もふくめて、事務作業のコンピュータ化は時代の流れですが、パソコンはシフトJISですから、ベンダーが独自に実装しているシステム外字をふくめても、6500字前後しか漢字がありません。法務省は、一時、一太郎の外字ファイルで人名異体字を配布しようとしたそうですが、外字として登録できるのは、わずか1880字です。この程度では、とうてい行政事務はまかなえません。地方自治体にパソコンを売りこむには、漢字をなんとかしてたくさん使えるようにする必要があるのです。
もしパソコンで人名漢字をカバーできるようになれば、地方自治体よりももっと大きな市場が控えています。オフコンや大型機が金城湯池としている企業市場です。
オフコンというのは、オフィスコンピュータを日本風に略した言い方です。オフコンは、ハードウェア的にはパソコンよりもすこし性能の高いマシンでしたが(現在は、パソコンの方が凌駕しているようです)、販売形態はまったく異なります。
パソコンの場合、ユーザーは出来合いのソフトウェア(パッケージソフトといいます)を買ってきて、自分でインストールし、カスタマイズして使いますが、オフコンの場合、販売会社は、ユーザーの業務内容にあわせて特注で作ったソフトウェア(カスタムソフトといいます)を、ハードウェアと抱き合わせで販売するのです。
特注で作るといっても、実際は出来合いのソフトウェアのマクロを、業務内容に合わせて書き換える程度のことがほとんどだったようですが、コンピュータの知識のない人には、そんなことはわかりませんから、かなりの金額を要求することができたのです。しかも、パッケージソフトと違って、違法コピーされる心配はありませんから、ひじょうに有利なビジネスでした。1992年の統計では、日本のソフトウェア販売額の90%近くはカスタムソフト(大型機をふくむ)で、パッケージソフトは10%にすぎなかったそうです。
パソコンの性能が上がり、使い勝手が以前より格段によくなるにつれ、こうしたビジネスはだんだんなりたたなくなっていきました。割高なオフコンや大型機をやめて、パソコンに置き換えようという動きが本格化したのです。いわゆるダウンサイジングですね。もっとも、日本の場合、大型機やオフコンは、パソコンに対して、まだ大きな優位性を保っていました。数万字におよぶ外字が使えることです。
Unicodeを実装したWindows NTは、漢字数・外字数とも約3倍に増えた点でシフトJISベースのMS-DOSやWindows3.1よりはましなものの、オフコンと大型機の市場を狙う人々にとっては、まだまだ不十分でした。CJK統合漢字は2万字といっても、日本漢字は1万2千字余にすぎず、肝心の人名異体字はほとんどはいっていません。外字は6400字です。社会慣行として、顧客の名前を間違って表記するのは大変な失礼にあたりますから、人名異体字をきちんと表記できるシステムには大きな需要があるのです。わずか1880字や6400字程度の外字領域しかもたないパソコンは、決定的に不利です。
Windows NTの外字には、もう一つ問題がありました。Windows NTはネットワークOSといって、社内のパソコンを構内ネットワーク(Local Area Network=LAN)で結びつけ、共同作業をおこなえるような仕組をつくれることが売りでしたが、外字はマシン・ローカルのものなので、ネットワークにはなじまない面があるのです。
Aという課員が、外字領域の中の"E001h"というコードポイントに「![]() 」という字形をわりあて、「
」という字形をわりあて、「![]() 田茂」という顧客の名前をワープロ文書に書いたとします。その文書を、LANを介してBという課員が見るとしましょう。Bのマシンの"E001h"に、「
田茂」という顧客の名前をワープロ文書に書いたとします。その文書を、LANを介してBという課員が見るとしましょう。Bのマシンの"E001h"に、「![]() 」という字形がわりあてられていたら、「
」という字形がわりあてられていたら、「![]() 田茂」さんは「
田茂」さんは「![]() 田茂」さんに化けてしまいます。これでは危なくて仕事になりませんね。
田茂」さんに化けてしまいます。これでは危なくて仕事になりませんね。
なんという欠陥システムだとあきれるかもしれませんが、外字は本質的に危険なものなのです。欧米では外字で人名を表記するなんていうことはまずありませんから、あまり問題になっていませんが。
外字をいかにして増やすか、いかにしてLAN上で共有するか──この二つの課題を一挙に解決する切札として考え出されたのが、WindowsNT拡張漢字処理(eXtend Kanji Processing=XKP)です。
XKPの中心になるアイデアは、構内ネットワーク(LAN)の上に文字識別情報データベース(Character Information Database=CID)という外字データベースを設け、そこで外字を集中管理しようという考え方です。文字識別情報データベース(CID)を置く場所を外字サーバー(Use Defined Character Serve=UDCサーバー)といいます。
従来の外字は、規格内文字と同じように、コードポイントであらわされていました。あるマシンで作成した文書や表には、そのマシンで定義された外字のコードポイントが直接書きこまれました(だから、他のマシンでは別の字に化けたわけです)。ところが、XKPでは、文字識別情報データベース(CID)に登録された文字識別番号であらわされます。文書や表に書きこまれるのも文字識別番号です。
XKPに対応したソフトウェアは、文書や表の中に文字識別番号を見つけると、構内ネットワーク(LAN)につながっているUDCサーバーに問い合わせ、文字識別情報データベース(CID)から字形データを送ってもらいます。受けとった字形データは、外字領域のあいているコードポイントにわりあてて表示します。外字領域がいっぱいになったら、使わなくなった字形データを捨て、新しい字形データといれかえます。
この仕組なら、構内ネットワーク(LAN)につながっているすべてのマシンで、同一の外字セットを共有できますし、6400字をこえる外字も使えますね。
言葉で書くと簡単ですが、実際は高度なネットワーク技術を駆使した複雑なシステムで、そのことはXKPの技術文書を見ても、肝心のUDCサーバーの実装詳細が規定されておらず、構内ネットワーク(LAN)の規模や性質によって適切な実装をするとなっていることからもあきらかです。
当然、XKPは高くつきます。XKPに対応したソフトウェアでなければ、XKP外字は符号にかこまれた8桁の数字(文字識別番号)にしか見えませんし、入力するにもXKP対応の日本語入力ソフト(IME)が必要です。また、将来的にはWindows95やWindows3.1でも使えるようにするということですが、当面はWindows NTでしか使えません。
今、日本のソフトウェア産業は大変なところに来ています。金城湯池だったオフコン市場は、ダウンサイジングにより消滅の危機に瀕しています。大型機の市場も切り崩されています。パソコンのパッケージソフトの市場も安閑とはしていられません。外圧から日本のソフトハウスを守ってきた互換性と日本語の壁は、WindowsとUnicodeによって粉砕され、世界市場を制覇したアメリカ製のパッケージソフトが、格安の値段で押し寄せてきています。データベースや表計算はアメリカ製ソフトの独擅場ですし、ワープロも一太郎が孤塁を守るだけという惨状です。日本のソフトハウスは、もはや正攻法では勝負できず、隙間商品でかろうじて食いつなぐありさまです。
皮肉にも、Unicodeの制約が、日本のソフトハウスにXKPという悲しい活路をあたえました。XKPでWindows NTの小判鮫となり、Windows NTの自治体制圧作戦とオフコン征服作戦にくっついていけば、当面、食いはぐれはありません。しかし、未来があるとも思えません。
XKPの仕様書には、「将来的な見通し」として、XKP外字をインターネットを介して共有するという意味のことが書かれていますが(ネットワーク化社会の到来を考えると、当然、その方向に進まざるをえないでしょう)、セキュリティの問題があります。
JISの83年改正で、「檜山」さんが「桧山」さんにすりかわったというおそまつは前章でふれましたが、政府の管理する文字セットですらこうなのですから、私人が文字セットを管理すると、同じようなトラブルがあちこちで頻発するのではないでしょうか。
孤立したマシンの外字セットなら、自分で作って、自分で使うだけですから問題は起こりにくいですが、構内ネットワーク(LAN)で外字を共有するとなると、自分の登録した文字が知らないうちに変えられていたという事故が起こらないともかぎりません。ましてインターネットを介して、他のサイトの外字セットを使うとなると、なにが起こるかわからないはずです。
XKP外字は人名異体字を主な用途としていますから、「![]() 田茂」さんと契約したつもりが、「
田茂」さんと契約したつもりが、「![]() 田茂」さんとの契約にすりかわっていたりなどという怖いことが起こらないとも限りません。
田茂」さんとの契約にすりかわっていたりなどという怖いことが起こらないとも限りません。
どんなに高度な技術を駆使しようと、外字は外字です。文書をいじらなくても、外字セットを細工することで、内容を改竄することができるのです。XKPは、悪意に対して、ひじょうに脆弱な仕組だと思います。
ネットワーク化社会には、外字はなじみません。「当事者間の合意」によって外字を定義しようにも、当事者が拡散してしまうからです。本格的ネットワーク化社会の到来を目前にした今、必要悪として使われてきた外字は歴史的使命を終えようとしているのではないでしょうか。
Copyright 1997 Kato Koiti
This page was created on Mar27 1997; Last updated on Jun21 1997 .