

コンピュータが普及すればペーパレス社会が実現するといわれていたが、コンピュータが導入されたオフィスでは、逆に紙の書類が増えるという皮肉な現象が起きている。CRTや液晶ディスプレイはブラウズするには十分だが、長文を熟読するには向かないからだが、ディスプレイの短所を解決するかもしれない技術が開発されつつある。電子インクである。電子インクは画面描き換え時にごく微量の電力を使うだけで、電源を切っても同一の画面が保持される。CRTや液晶ディスプレイのような発光体ではなく、紙と同じように反射光で視認されるので、目にやさしいし、機械加工の工程がすくなく、大量生産で急速に安くなると期待されている。
電子インクの最初の製品は1999年にE INK社から発売されたImmedia Displayである。まだ1インチ角の大きな文字しか表示できないものの、厚さ3mmで紙のように丸めることができる。電子インク技術は多くの企業が開発を競っており、2003年頃には紙の代わりになる製品が出てくるといわれている。
電子インクは紙を浪費している先進国のオフィスだけでなく、途上国の教育現場にも朗報をもたらす。山間部や島嶼部の学校に、新学期までに新しい教科書を配布するのは難事業だが、電子インクの教科書なら、携帯電話とパソコンを学校に一台用意しておくだけで、最新の教材を教室にとどけることができるだろう。
文書を電子化するには画像方式と文字方式がある。画像方式は文書をファクシミリで電送する際のように、明暗の点の集まりとして記録するもので、画像と同じである。文字方式は文字を番号に置きかえ、文書を数字の集まりとして記録する。文字を表す数字を文字符号、文字と番号の対応を定めた規格を文字コードと呼ぶ。コンピュータでは文字の削除、追加、複写、ペースト、検索、置換といった操作を「編集」と呼ぶが、画像方式では編集が不可能なのに対し、文字方式では自在にできる。インターネット上の膨大な文書の中から、該当文書を一瞬で探しだすことも可能だ。
コンピュータの進歩は著しいが、テキストのきちんとした表示のできない言語、表示はできても編集で不具合のある言語はすくなくない。また、大半のシステムでは、英語と自国語の二ヶ国語同時処理はできても、多言語処理はできない。最後の節でふれるユニコードを使ったシステムでは、欧米の言語間の多言語処理は実用のレベルに達しているが、アジアの言語の処理や多国語処理では課題が残っている。
コンピュータはアメリカで発達したが、現代英語は世界でも稀に見る単純な表記体系をもった言語で、アルファベットの大文字と小文字と数字、コロン、ピリオドなど、70ほどの文字ですべての語を表記することができる。アメリカの工業標準として誕生したASCIIはもっとも基本的な文字コードで、各国の文字コードはASCIIを雛形に作られている。
アルファベットは音素文字で、子音字と母音字を組みあわせて単語を綴るが、英語以外の言語では、フランス語のéやçのように、音素の違いをダイアクリティカルマークで明示したアルファベットを使う。当初は「è」を「e + `」のように、基底文字とダイアクリティカルマークの組みあわせで符号化したが、現在は独立の文字として符号をあたえるのが一般的である。ヨーロッパの言語の場合、ASCIIに10~30程度のダイアクリティカルマーク付きアルファベットを追加すればよいが、ベトナム語のコックグーでは200近い追加が必要である。
中国、台湾、韓国、日本で使われている漢字は桁違いに多い。日常的な文章でも三千字は必要だし、一般的な漢字字典で一万字、世界最大の漢字字典は八万字を収録している。
コンピュータの技術的な制約から、文字をあらわす符号は0~127までの番号(7桁の2進数で、7bitという)を使うのが一般的だが、漢字は数が多いので、二つの番号を組みあわせた符号をあたえる。マルチバイト・コードである。
公的な文字コードにない漢字が必要な場合は、文字の割りあてられていない空き符号を使って、ユーザーが独自に文字を定義する。これを外字というが、紙に印刷する分には問題はないものの、ネットワークでは別の文字に化けてしまう。
漢字が複雑で数が多いのは、「山」はmountain、「木」はtreeのように、一文字で単語をあらわす場合が多いからである。英語の歴史の中で綴りが変化したように、漢字の字形も変化し、別字と見なされるようになる場合がある。蒸気機関の発明者のStephensonと作家のStevensonが区別されるように、日本では「高崎」と「髙﨑」が区別されている。その一方、単なるデザイン差と見なされるケースもある。字形の違いをどこまでをデザイン差とし、どこからを別字とするかという問題は後々まで尾を引くだろう。
アラビア文字はアラビア語の特性により、原則として子音字だけで単語を綴るが、位置によって字形が変わる。bにあたる は語頭では
は語頭では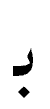 、語中では
、語中では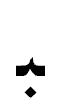 、語尾では
、語尾では になる。また、リガチャーという現象があり、ドイツ語でssが ß になるように、
になる。また、リガチャーという現象があり、ドイツ語でssが ß になるように、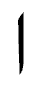 と
と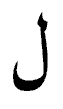 が結合して
が結合して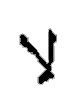 に変化する。
に変化する。
変化した字形を別の文字として符号化すると、削除、追加、検索といった編集が困難になるので、今日では編集用の符号と、表示用の符号を分離する方式が推奨されている。編集時には語頭形、語中形、語尾形、独立形を同一の符号であらわし、はとという二文字としてあつかうが、画面に表示する際には表示用の符号に変換する。
アラビア文字は印欧語系のペルシャ語、ウルドゥー語、アルタイ語系のウイグル語など、アラビア語と系統を異にする言語でも使われているが、こうした言語では独自の子音、母音、音節区切文字をあらわす工夫をしており、別の表記体系と考えた方がよい。
世界最初の文字は母音の表記を必要としないハム・セム語圏で生まれたので、もともと母音をあらわす文字はなかった。西方に伝わると、ギリシアで母音字が追加され、アルファベットの原型となった。インドでは子音字に母音をあらわす記号を付加することで音節をあらわした。結合音節文字である。タイ文字やミャンマー文字、チベット文字、韓国語のハングルも結合音節文字といえる。
同じ母音でも、単独の母音か子音と結合して音節の一部となる母音かで字形が異なる場合があるし、リガチャーも多い。ハングルは15世紀に作られた比較的新しい結合音節文字で、整然とした体系をもっているが、それでも理論的に可能な組みあわせ形は一万を越える。韓国の要望で、ユニコード=ISO 10646ではハングルのすべての組みあわせ形を収録したが、他の結合音節文字では組みあわせ形は天文学的な数にのぼり、すべてを収録するのは現実的ではない。結局、字母の組みあわせで表現するしかないが、どうのような組みあわせをもって一文字とするかを厳密に定義しておかないと、編集で問題が生じる。
各国の公的文字コードは、ISOが決めたISO 2022に準拠している。オリンピック開会式では、各国選手団は国名を書いたプラカードを先頭に行進するが、ISO 2022もそれに似ていて、テキスト冒頭に識別符号をつけて、どの文字コードで符号化したかを明示することになっている。ISO 2022は1973年に制定されたが、当時、非アルファベット圏からの唯一の代表だった日本の和田弘が強く求めたマルチバイト拡張が盛られており、漢字コードを整合的に開発することが可能になった。
ISO 2022は通信を念頭においた規格なので、コンピュータの内部処理には向いていない。インターネットが普及するまでは、英語と自国語の二国語処理ができれば十分だったので、日本ではISO 2022準拠の公的文字コードを変形して、シフトJISとEUCという内部処理用文字コードがつくられた。パソコンではシフトJIS、UNIXワークステーションではEUCが一般的である。中国と韓国ではパソコンでも公的文字コードをEUC方式で使っている。台湾・香港ではシフトJISの影響を受けたBig5が普及している。
本来なら、メールを送ったり、記録媒体に記録する際には、内部処理用のコードをISO 2022準拠の公的規格の文字コードに変換すべきだが、内部処理用文字コードをそのまま外部に出す時代がつづいた。内部処理用コードはプラカードにあたる識別符号がないので、どの文字コードか特定できず、インターネットが一般的になると問題が表面化した。
ISOでは1983年からISO 2022を発展させた国際文字コードの策定をはじめた。それとは別に、アメリカでは経済のグローバル化をにらみ、ユニコードという16bitの国際文字コードの開発がはじまった。ISOはユニコード・コンソーシアムの強い要望で共同歩調をとることになり、1993年に完成した両文字コードは同一の内容で、1990年時点における各国の公的文字コードの文字を統合した上で収録しており、ISO 2022との互換性はない。16bitコードは2の16乗にあたる6万5千余の文字を収容できるが、全世界の文字をおさめるには不十分なことがわかり、サロゲート・ペア(UTF-16)という手法で百万字分の符号が追加された。当初、漢字は2万字だったが、6万字余に増やす方向で作業が進んでいる。
アラビア文字圏と結合音節文字圏では、国内に複数の文字コードが併存している国がすくなくない。行政上の混乱や、海外から来た援助団体が当座の必要に迫られて独自文字コードを作り、使いつづけているケースもあるが、文字の特性にも原因がないとはいえない。こうした表記体系では、母音記号が結合した子音字やリガチャーが、単純な合成では出せない字形をとることがある。大半の文字コードでは、コンピュータのレンダリング能力をおぎなうために、変形した字形を独立の文字として符号化している。基本の字母セットは一致しても、表示形をどこまで収録するかで意見の相違が出てくるし、編集上の単位をどう定義するかで議論がわかれることもあるようだ。
日本のCICCは、日本政府の委託を受けて、1987年からアジア諸国の情報化に協力するために、AFSIT(Asian Forum for Standardization of Information Technology)というプロジェクトを進めているが、 その一環として1997年からアジア諸国に呼びかけて、MLIT(Multilingual Information Technology)という会議を開催し、Equal Language OpportunityとMultilingual Processing Environmentを合言葉に、編集用文字コードと表示用文字コードを分離する最新のテキスト処理技術や、文字コードのアーキテクチャ、特別な訓練を受けたオペレータでなくても自国語を打ちこめる自然な入力方法、ISOに自国の文字を登録する手続などについて、意見交換の場を設け、多大の成果をあげた。1999年と2000年には特に問題をかかえた国に助言するために、SEISA AP/ITという技術セミナーを開いている。一連の会議で発表された報告と論文はMLITのサイトで公開されており、アジアの国々がどのような問題に直面しているかがわかる。
漢字圏では外字が情報交換のネックになっているが、数万字規模の文字ライブラリを共有することで、外字をネットワークでも使えるようにしようという試みがはじまっている。いくつかのプロジェクトがあるが、最も普及しているのは日本の文字鏡研究会の文字セットである。これには漢字八万字の他、甲骨文、篆書、ベトナムの字喃や西夏文字、水文のような中国周辺で作られた疑似漢字が国際的な協力のもとに収録されている。フォントと漢字の字源にもとづいた検索ソフトはエーアイ・ネットAI-NET Co.,Ltdが製作し、紀伊國屋書店が販売しているが、文字鏡研究会はアウトライン・フォントと文字を検索し利用するためのソフトの無償配布を(株)エーアイ・ネットより100年間委託されており(配布権は2098年10月まで有効)、同研究会のFTPサイトからダウンロードして利用することができる。また、文字鏡研究会と(株)エーアイ・ネットはインターネット上で文字図形の提供もおこなっており、該当する文字の画像ファイルのURLを書きこむことで、WWWページでも外字を表示することができる。
今後、ユニコード=ISO 10646が主流になっていくと思われるが、対応したソフトウェアはまだ多くないし、世界中に蓄積されているデータのほとんどはISO 2022系文字コードで符号化されている。一部のソフトでは実体参照という技術によって、ISO 2022系文字コードで符号化されたテキスト内でも、ユニコード=ISO 10646に収録されている文字を表示できるようになったが、今のところ編集は難しい。特別な知識がなくても使える多言語環境の実現までには曲折が予想される。
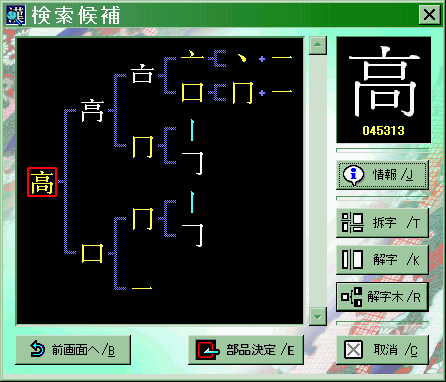 |
文字鏡の漢字データベースは「拆字」と呼ばれる字源にもとづく体系によって構築されている。「高」は高さをあらわすが、甲骨文では である。この字形は高楼
である。この字形は高楼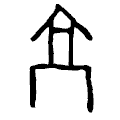 の前に祈祷文をおさめた箱
の前に祈祷文をおさめた箱 を置いたさまを象っている。「高」は高楼の前でおこなう戦勝祈願をあらわしている。
を置いたさまを象っている。「高」は高楼の前でおこなう戦勝祈願をあらわしている。