JISの基本となる漢字コード、JIS C 6226(JIS X 0208)はいくつかの段階を踏んで開発されたが、情報処理学会漢字コード委員会が1971年にまとめた「標準コード用漢字表(試案)」においてほぼ原形が固まったと思われる。
当時試作されていた漢字処理システムの多くは、漢字テレタイプの影響から、二〜三千字を収録するにとどまっていたが、漢字コード委員会を発足させた和田弘は、将来の技術的進歩を見越し、ISO/IEC 2022の2バイト枠(94×94=8836字)をめいっぱい使うことを選んだ。
この方針を受けて、実際に文字の選定にあたったのは国立国語研究所の林大だった。林は1974年発足の「漢字符号標準化調査研究委員会」、1976年発足のJIS原案委員会で作業を継続し、JIS C 6226の6349字の漢字セットをまとめた。
JIS C 6226は94行94列のコード表という器にあわせて文字を選定した。コード表の横行を「区」、縦列を「点」と呼び、個々の文字は区点番号で特定することが多いが、実際の符号としてはGL領域を使う7ビットコードか、GR領域を使う8ビットコードになる。
1〜7区は数字、アルファベット、カナ、記号類などをおさめる非漢字領域、16〜47区は使用頻度が高いと推定される漢字をおさめた第1水準漢字領域、48〜83区は使用頻度が低いと推定される漢字をおさめた第2水準漢字領域である。
JIS C 6226の漢字セットは名簿用途を考慮して、地名漢字と人名異体字をかなり収録していたが、万全ではなかった。外字(ユーザーが空き符号に独自に登録した規格未収録文字)の使用が予想されたので、JIS C 6226では外字に使ってよい自由領域と、使ってはいけない制限領域を設けた。自由領域とされたのは非漢字領域と漢字領域の間と、第2水準漢字領域の後ろのまとまった空きである。非漢字領域に点在する空きや、第1水準漢字の最後の区の空きは、将来の拡張にそなえて制限領域とされた。
JIS C 6226には非漢字463字もはいっていて、ASCII(≒JIS C 6220)収録字をすべてふくむが、だからといってASCII(≒JIS C 6220)が不要になったわけではない。
当時のコンピュータは「RUN」のようなコマンドを打ちこんで操作した。コンピュータはアメリカ生まれなので、JIS C 6226で「RUN」と命令しても通じず、ASCII(≒JIS C 6220)で「RUN」と打ちこまなければならなかった。日本のコンピュータは(他の漢字文化圏の国々も同様であるが)、宿命的な条件として、2バイト・コードであるJIS C 6226と、1バイト・コードであるASCII(≒JIS C 6220)のバイリンガルでなければならない。
欧米のコンピュータはアルファベットを縦横比2:3、5:7、7:9で表示した。日本でも当初は欧米方式を踏襲していたが、1バイトのJIS C 6220(≒ASCII)と2バイトのJIS C 6226を共存させる場合、当時の技術的な制約から、文字のバイト数と表示幅をあわせる必要があった。そこで、1バイトのJIS C 6220の文字を、2バイトのJIS C 6626の文字の半分の幅で表示するという変則的な実装が日本で一般化した。印刷の世界では縦横比2:1の縦長の活字は「半角」、縦横比1:1の正方形の活字は「全角」といったので、JIS C 6220の文字は慣習的に「半角文字」、JIS C 6226の文字は「全角文字」と呼ばれるようになった(JIS C 6220の規格票の例示字形は普通の横幅で印刷されており、2:1の縦長にするというような規定はない)。
JIS C 6220とJIS C 6226には同一の文字が重複してはいっているが、JIS C 6220のカタカナは「半角カタカナ」、JIS C 6226の方は「全角カタカナ」と呼んで区別するのが一般的である。好ましいことではないが、規定外の形状の差に注目して、「半角カタカナ」を特別なニュアンスをともなった文字として使用することが一般化している。
JIS C 6226はJISに情報処理部門が設けられると、JIS X 0208と名称を改めたが、内容もたびたび改定されている。各規格を区別するために、改定年次にもとづいて、1978年の第一次規格を78JIS、1983年の第二次規格を83JIS、1990年の第三次規格を90JIS、1997年の第四次規格を97JISと呼ぶことが多い。目につく字形の変更は1983年が著しかったが、他の改定時も、設計思想の面でかなり変遷がある。特に重要なのは1997年の改訂である。
97JISでは新たな文字の追加・字形変更はおこなわなかったが、JIS X 0208の字形の変遷史を洗いだし、字形のゆれの許容範囲を包摂規準として明文化するとともに、重複符号化禁止の規定を盛りこみ、包摂される範囲の異体字が独立の文字としてあつかわれないように定めた。
90JISまでの文字セットは異体字に対して開かれていたが、重複符号化の禁止によって、JIS X 0208の文字セットははじめて閉集合になったといえる。97JISによってJIS X 0208は大きく性格を変えた。
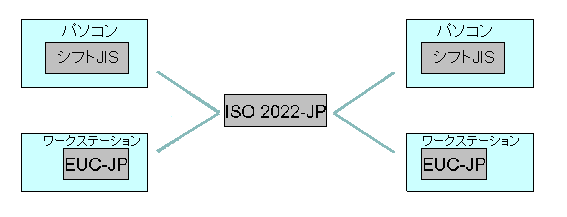
ISO/IEC 2022は国際的な情報交換を念頭においた規格だが、インターネットが普及するまでは、英語と自国語の二国語処理ができれば十分だったので、日本ではISO/IEC 2022の構造を変形したシフトJISとEUC-JPという内部コードがが普及した(パソコンではシフトJIS、UNIXワークステーションではEUCが一般的)。
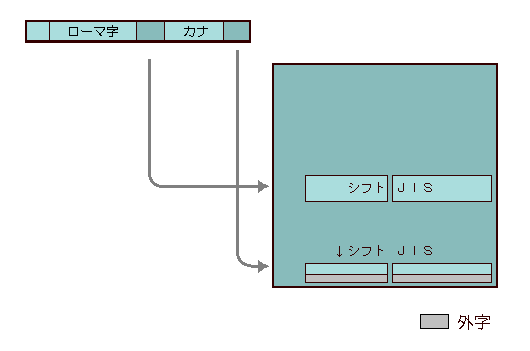
シフトJISはJIS C 6220の8ビット拡張版を基本とし、カタカナを収録が配置されているGR領域の空き番号を第1バイトとして2バイト・コードを構成し、JIS C 6226の文字セットを流しこんでいる。
第1バイトとなるGR領域の空き番号は64しかないので、1区に188字(94×2、つまりJIS X 0208の2区分)詰めこんでおり、第1バイトとして必要な番号は47で済んでいる。シフトJISはあくまでISO/IEC 2022の構造の変形であり、簡単な数式でJIS X 0208と変換できる。[図3]
|
| 33〜126、161〜223はそのままJIS X 0201の符号として用いる。129〜160と224以降(JISローマ字カナの空き番号)は漢字の第1バイトとして用いる。漢字の第2バイトには64〜126、128〜252の範囲の番号を用いる。 |
第1バイトとして使える番号が17余っているが(64 - 47=17)、この部分はなし崩し的に外字領域になってしまった(ISO/IEC 2022の94x94の文字面に対応位置をもたない。後述するJIS X 0213では第2面に対応させ、第4水準としている)。
EUCはExtended Unix Code(拡張UNIXコード)の略で、日本語UNIX諮問委員会が策定し、国際的なUNIX関連諸団体から認知されている。EUCの原案が固まった後、ISO/IEC 2022はEUCと整合するように改訂された。EUC方式は2バイト・コード一般に適用可能なので、中国語版のEUC-CN、韓国語版のEUC-KRがある。
EUC-JPはISO/IEC 2022のGL部分をASCIIに使い、GR部分を8ビット版のJIS X 0208にあてる。後半の制御符号領域のシフトイン・シフトアウトを頭に付けることによってJIS C 6220のカタカナ(半角カタカナ)とJIS X 0212(JIS補助漢字)を使うこともできるが、そこまで実装しているシステムは多くない。[図4]
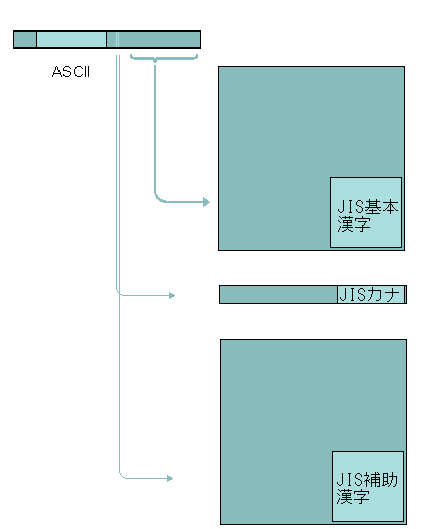 |
| 33〜126はASCII、161〜154はJIS X 0208、142は次の1バイトと組みあわせてJISカナ、143は次の2バイトと組みあわせてJIS X 0212(補助漢字)として解釈する。 |
メールを送ったり、記録媒体に記録する際には、内部コードをISO/IEC 2022準拠の外部コード(JIS X 0208)に変換してから出力するのが本来の使い方だが、1980年代当時はネットワークについての認識が浅く、パソコンなどではとりあえず動けばいいという場当たり的対応が多かった。そのため、内部コードであるシフトJISをそのまま出力する時代がつづき、シフトJISによる情報交換がなし崩し的に一般化してしまった。シフトJISは外部コードとして設計されたわけではないので、情報交換に用いると問題がおこる。インターネット上の文字化けの半ばはシフトJISが原因となって発生している。
インターネット・メールに限っていえば、JUNET時代に原形のできたISO 2022-JP(RFC 1468)に変換して送りだすのが一般的である。ISO 2022-JPは7ビット版のISO/IEC 2022にいくつかの制限を追加したもので、通信エラーに強くなっている。[図5]
 |
2000年に日本はJIS X 0213を制定した。JIS X 0213はISO/IEC 2022準拠の94×94の文字面を2面使う文字コードで、JIS X 0208といっしょに使うことを前提としている。第1面はJIS X 0208の隙間に文字をマッピングしており、第3水準と称する。第2面はJIS X 0212(補助漢字)の隙間にはいるように配置されており(注3)、第4水準と称するが、実はシフトJISの外字領域以降にちょうどおさまるように字数が決められている。
JIS X 0213の文字セットはシフトJISという器にあわせて作られたという点で、それまでのISO/IEC 2022準拠のJIS漢字コードとは性格がかなり異なる。最初にシフトJISありきなので、シフトJISのフォントをJIS X 0213対応のものに交換すれば4千字ほどの漢字が増補できるわけだが、Windowsなどのシステム外字とぶつかるので文字化けが避けられない。日本工業標準調査会(JISC)の部会審議の段階で、大手メーカー2社の代表が多くのベンダーの支持を背景に、シフトJIS隙間実装を規定した付属書に異議を表明し、JIS X 0213のシフトJIS隙間実装を規定した付属書は「参考」のあつかいになった。JIS X 0213で増えた文字は後述のユニコードの一部として使われることになる。
中国(中華人民共和国)は1980年にGB 2312を制定した。GB 2312は94×94のISO/IEC 2022準拠の文字コードで、最初に記号類、数字、アルファベット、ピンイン、注音字母など非漢字を置き、JIS C 6226同様、16区から漢字領域になる。漢字は使用頻度の高い第一級漢字3755字と低い第二級漢字3008字にわかれ、第一級漢字はピンイン順、第二級漢字は部首順にならべられている。
GB 2312はJIS C 6226に酷似しているが(カナはJISと同じ符号位置)、実は開発にあたり、中国はJIS原案委員会の西村恕彦らを招聘し、翌年にはJIS批判派と目されていた田嶋一夫をまねいて指導を受けていた。
GB 2312は基本集という位置づけであり、1987年に二つの補助集がつくられ、2万字をこえる簡体字が符号化された。簡体字コードに相当する伝統字版補助集もつくられたが、文字コードを切り替えるだけで変換できるように、「贝」の位置に「貝」を置くというように、マッピングを同じにしている。しかし、GB 2312収録漢字の2/3は簡略化をこうむっておらず、簡体字版と伝統字版は4千字以上もの漢字を重複収録している(重複字の多いことが、後に中国がユニコード支持にまわる一因になったらしい)。なお、簡略化の際に統合された103字(「發」と「髪」→「发」)は一方を88区以降に収録しており、簡体字→伝統字変換では文字化けが起こる。
中国にはカナがないので、ASCIIとの共存はEUC-CNで可能である(パソコンとワークステーション両方でEUC-CNが標準)。
台湾(中華民国)では1980年に台湾中央図書館と國字整理小組がCCCII(ChineseCharacter Code for Information Interchange, 中文資訊交換碼)という3バイトの書誌用漢字コードを作ったが(次章参照)、3バイトなので図書館分野以外ではあまり使われなかった。
CCCIIを国家標準にしようという動きもあったというが、中華民国経済部ではそれとは別に2バイトの漢字コードを準備していた。当初は漢字をコードポジションの一つおきに配列し、4面使うという独自構造をとっていたが、日本側関係者の助言もあり、最終的にISO/IEC 2022準拠のCNS 11643が制定された(注4)。
CNS 11643は94×94の符号表を16面用意していたが、1986年に発表されたのは最初の2面だけである。第1面は非漢字と使用頻度の高い第一級漢字5401字、第2面は使用頻度の比較的低い第二級漢字7650字を収録する。1988年には第14面が、1992年には第3〜7面と戸籍用漢字をおさめた第15面が増補されている。
CNS11643は制定までに紆余曲折があったので、大手コンピュータ会社5社と資訊工業策進会は1984年に試案段階だったCNS11643の最初の2面をシフトJIS方式で並べかえたBig5(大五碼)を発表した(注5)。
Big5はシフトJIS同様、なし崩し的に外部コード化してしまい、香港・マカオを含む伝統字圏のデファクト標準となった(ただし、独自に拡張したローカル版が多いという)。Big5は正式版のCNS11643とは若干の異動があるので、相互変換には変換表が必要である。
台湾はCNS11643を国際登録簿に登録しようとしたが、長らく棚ざらし状態がつづいたために、その間使っていた臨時の識別番号と正式の識別番号が並立するという情況がうまれている。
ハングルは結合音節文字で、初声、中声、終声の三字母で一文字を構成する(子音・母音・子音)。字母の組みあわせは理論的には11172通り可能だが、現代韓国語の表記には2千程度で十分という。
字母の数は初声字19字、中声字21字、終声字27字で、二重母音に独立の符号をあたえたとしても70前後である。ハングル完成形を字母符号の組みあわせであらわすなら、ISO/IEC 2022の94字の枠内におさまり、1バイトコードで間にあう。だが、ハングル完成形に直接符号をふっていくと、数千字分の符号が必要になり、2バイトコードが必要になるし、すべてのハングルを符号化しようとすると1面ではおさまらない。
1974年に制定された最初のKS C 5601はISO/IEC 2022準拠の1バイトコードで、ハングルを字母の組みあわせであらわした。しかし、漢字との併用が困難なため、2バイトコードの模索がつづけられ、1987年にいたって、KS C 5601の改訂版が制定された。
1987年版KS C 5601は最初に記号類、数字、アルファベット、ハングル字母等を置き、16〜40行にハングル2350字を、42〜93行に漢字4888字を配置している。いわばJIS C 6226の第1水準領域にハングル完成形、第2水準領域に漢字をマッピングしたようなもので、構造が酷似している(注6)。
ハングル専用を国是とする国だけに、漢字は読み順でならべ、複数の読みのある漢字は重複登録されている。韓国語に訓読みはなく、音読みは原則的に一字一音なので、複数の読みをもつ字は5%程度という。
1991年にはKS X 1002が制定され、使用頻度がそれほど高くないハングル完成形3605字と漢字2856字を収録した。韓国はハングル専用を国是としたので漢字は簡略化せず、伝統的な字体を残している。ASCIIとの共存はEUC-KRでおこなう。
北朝鮮(朝鮮民主主義人民共和国)は1997年にKPS 9566を制定した。KPS 9566はISO/IEC 2022準拠の2バイト・コードで、最初に記号類、数字、アルファベット、キリル文字等を置き、16〜44区にハングル2679字、45〜94区に漢字4653字を配置している。社会主義国らしく、二代にわたる国家指導者の名前を表記するためのキム・イル・ソン、キム・ジョン・イルというハングル6字を重複登録しており(ISO/IEC 10646に追加申請していたが、ぎりぎりのところで取りさげた)、韓国のKS X 1001との互換性はない。
Copyright 2004 Kato Koiti