�@ISO�̓A�����J�̔��c�ɂ��A1983�N����ISO/IEC 2022�̉�������̍��ە����R�[�h�AISO 10646�̊J���ɒ��肵�Ă����B1989�N��4�o�C�g�Ɋg�������ŏ��̌��Ă��܂Ƃ܂������A�ŏI�i�K�̍��ۓ��[�Ŕی����ꂽ�B�ŏI���[�܂ł����Ȃ���ی����ꂽ�̂́A�A�����J�����j�R�[�h�iUnicode�j���i�ɕ��j��]����������ł���B
�@���j�R�[�h�Ƃ̓A�����J�̃t�H���g�W�҂𒆐S�ɐi�߂��Ă������E���ʓ����R�[�h�̊J���v���W�F�N�g�ŁA16�r�b�g�Œ蒷��6��5�玚�]�̃X�y�[�X�ɑS���E�̂��ׂĂ̕��������^���悤�Ƃ�������ȗ��z���������Ă����B
�@���j�R�[�h�Ƃ������̂� Universal�i���ՓI�j�AUniform�i�Œ蒷�j�AUnique�i��ӓI�j�Ƃ������b�g�[�ɂ��ƂÂ��B16�r�b�g�Œ蒷�Ƃ����_�͍ŏ�����^�₪���������A�Œ蒷�����Ƃ���A�s�[�������̂́A���������p�̃R�[�h�Ƃ��č\�z���ꂽ���߂ł��낤�B
�@�����̓{�����e�B�A�E�x�[�X���������A�ɓ������ɐ��i�����[�J���C�Y����ώG�ȍ�ƂɔY�܂���Ă����A�����J�̃R���s���[�^�ƊE�̒��ڂ���Ƃ���ƂȂ�A1991�N�AIBM�ЁA�A�b�v���ЁA�}�C�N���\�t�g�ЁA�A�h�r�ЂȂǁA�B�X�����Ƃ��Q�����āA���j�R�[�h�E�R���\�[�V�A�����ݗ����ꂽ�B
�@��p�A�؍��ȂǁA�����������̏�����1980�N��ɖڊo�܂����o�ϔ��W���Ƃ��A�R���s���[�^�̗L�]�Ȏs��ƂȂ������A2�o�C�g�R�[�h�ւ̑Ή��͂����ł�����Ԃ��������ɁA�����Ƃɕ����R�[�h���قȂ����̂ŁA���{������A�ɑ̎�����������A�ȑ̎�����������A�؍�������ƁA�������i���l�[�J���C�Y���Ȃ���Ȃ�Ȃ������B�������������ʊ����R�[�h�ł����Ȃ��A�O���ɏo�͂���ہA���̍��̕W�������R�[�h�ɕϊ�����悤�ɂ���A���[�J���C�Y�̎�ԂƊ��Ԃ͑啝�Ɍy�������B
�@���ۋ��ʕ����R�[�h�Ƃ����_�ł�ISO 10646�̍ŏ��̌��Ă����������A�ŏ��̌��Ă͏���������ɐv����Ă����̂ɑ��A���j�R�[�h�͂����Ɏ��p�ɋ�������������p�R�[�h�Ƃ����ʂ��d������Ă����悤�ł���i��7�j�B
�@�����Ɏg����悤�ɂ��邽�߂ɂ́A�ǂ����Ă�16�r�b�g�ł������Ȃ���Ȃ�Ȃ������BISO 10646�̍ŏ��̌��ẮA32�r�b�g�̍L��ȃX�y�[�X�ɓ����ؑ�̌��I�����R�[�h�����̂܂��^���邱�ƂɂȂ��Ă������A16�r�b�g�R�[�h�ɂ�6��5�玚���̃X�y�[�X�����Ȃ��̂ŁA����ȗ]�T�͂Ȃ��B�����Ŏg��ꂽ�̂��A���������Ƃ�����@�ł���i���ߎQ�Ɓj�B
�@ISO/IEC 10646�̓��j�R�[�h�ƍ��̂�����Ă�����A1993�N�A�����ɍ��ۋK�i�ƂȂ����B���ꂪISO/IEC 10646-1�ŁA�R�[�h�\�����K�肵�������ƁABMP�iBasic Multilingual Plane, ��{������ʁj�̕����\����\������Ă���BISO/IEC 10646�͐��E���̕�����ԗ�����Ƃ��납��AUCS�iUniversal Coded character Set, ���ە����������W���j�Ƃ��Ă�Ă���B
�@UCS��32�r�b�g�R�[�h�Ƃ�����g�͈ێ��������A8�r�b�g4�o�C�g�ł͂Ȃ��A32�r�b�g1�o�C�g�ɂȂ����i��q��UCS2�̏ꍇ��16�r�b�g1�o�C�g�j�BISO/IEC 2022�Ƃ̌݊����͖������A���j�R�[�h�Ɠ��l��16�r�b�g�̕����ʁi6��5�玚�j��3��2�疇�]�W�߂��\�����Ƃ�A21���������e�\�ł���i�ŏ�ʃr�b�g�͂˂�0�ɂ���̂ŁA����31�r�b�g�j�B
�@�ŏ��̖ʂ�BMP�i��{������ʁj�ƌĂԂ̂͑�ꌴ�ĂƓ��������A���������������j�R�[�h���̂��̂ɒu��������ꂽ�B
�@����I�Ȃ̂́ABMP�Ɍ���A16�r�b�g�R�[�h�Ƃ��Ă������Ă悢���Ƃɂ����_�ŁA�����UCS2�Ə̂���BUCS2�́A���A���j�R�[�h�ł���B
�@���j�R�[�h��16�r�b�g��1�o�C�g�Ƃ�����������p�R�[�h�Ƃ��ĊJ�����ꂽ�̂ŁA�l�b�g���[�N�ɗ����ꍇ��UTF�iUCS Transfomation Format�AUCS�ϊ��`���j�ƌĂ��ʌ`���ɕϊ����邱�ƂɂȂ��Ă����B
�@���܂��܂�UTF����Ă��ꂽ���A�ŏI�I��UTF-8�������̂������B���j�R�[�h�͖`��������ASCII�����̂܂��^���Ă��邪�AUTF-8��ASCII���������̕����͂��̂܂o�͂��i���m�ɂ����A����0������8�r�b�g�ɂ���j�A�ȍ~�̕����́A�l�b�g���[�N�ɗ����Ă����̂Ȃ�2�`6�o�C�g��8�r�b�g�����̑g�݂��킹�ɕϊ����Ă���o�͂���B���j�R�[�h��ASCII�̏�ʌ݊��ł��邩�̂悤�ɂ�������_��UTF-8���I�ꂽ�傽�闝�R�̂悤�ł���B
�@�����Ń��j�R�[�h���\�ɂ������������ɂ��Ăӂꂽ���B
�@��Ɏ��烆�j�R�[�_�[�Ɩ���邱�ƂɂȂ�Z�p�҂����́A1980�N�㔼����ARLG�iResearch Library Groupe�A�S�Đ}���ُ��O���[�v�j�����肵��EACC�iEast Asian Common Character ���A�W�A���ʕ����\�j�Ƃ��������p�����R�[�h�����ƂɁA�����f�[�^�x�[�X�̍\�z��i�߂Ă����B
�@EACC�̌��ɂȂ����̂͑�p�̑�k���������}���ق��J������CCCII�Ƃ��������p�����R�[�h�������BCCCII�͑S�̂�16�Q�ɃO���[�v�킯���A��1�Q�ɓ`���������^���A��2�Q�ɂ͓`�����ɑΉ�����ȑ̎��A��3�`12�Q�ɂّ͈̎��A��13�Q�ɂ͓��{�̎��́A��14�Q�ɂ͊؍��̎��̂��}�b�s���O�����B�܂�A�����\�����̂܂܈ّ̎��f�[�^�x�[�X�ɂȂ�悤�ȍ\�����Ƃ��Ă����̂ł���B
�@RLG�͓��{�̓c����v�́u��������V�X�e���̉ۑ�v�̎����ɂ��i��8�j�A�ّ̎����ʒu�Ƃ͕ʂ̕��@�ł���킷�Ƃ�����@��͍����Ă����B���j�R�[�_�[������RLG�̍l�����P���A�ّ̎��̓t�H���g�Z�p�ɂ���Ă���킷�Ƃ��������ŋc�_��i�߁A1998�N���A2��������Ȃ�ŏ��̊����Z�b�g���܂Ƃ߂��B
�@�K�i�ɂ���Ĕ����Ɏ��̂̈قȂ銿���͈�̕����ɓ������ꂽ�B���������ł͈�̕����ł����Ă��A�o�͂���ۂɌ��̕����R�[�h�ɂ��ǂ��A�����K�i�Ƃ̎��̂̈Ⴂ�͕\�ʉ����Ȃ��B�܂��A�X�̎��̎��`�f�[�^���O���t�A�O���t�̏W�����t�H���g�Ƃ������A���i�Ɏ��������t�H���g�́A���j�R�[�h���^�������ׂĂ��܂ޕK�v�͂Ȃ��A���̍��̊����K�i�Ɋ܂܂�鎚�̃O���t�����ł悢�Ƃ����l�����ł���i��9�j�B
�@���j�R�[�h�W�҂͍��ۋ��ʕ����R�[�h��ISO 10646�ƃ��j�R�[�h�̓����������͍̂D�܂����Ȃ��Ƃ��āA���҂̍��̂��咣���A�A�����J�̑��R���s���[�^��ƌQ�̎x���̂��Ƃ�ISO�����e����������Ă܂�����B����ɑ��āA���{�͊��������ɂ͍����I���ӂ������Ȃ����ƁA�����̕����R�[�h�Ƃ̕ϊ��̍ہA���x�i���`�̗h��̋��e�͈́j�ɂ��ꂪ�����邱�Ƃ𗝗R�ɂ����AISO 10646�ƃ��j�R�[�h�̍��̂ɔ������B
�@���{�̔��c�ɂ���āA���������̐�����c�_���邽�߂ɁACJK-JRG�iCJK Joint Resarch Groupe, �����؍��������ψ���j�Ƃ����Վ��@�ւ��ݒu���ꂽ�B�����؍��������ψ���͐��x���ISO����Ɨ����Ă������AISO/IEC��ꍇ���Z�p�ψ�������ψ���Ɩ��ڂȊW�ɂ���A�����I�ɂ͂��̉����ψ���Ƃ����Ă悩�����B
�@�����؍��������ψ���ɂ͊��������������ƒn��i���`�j�̑�\�ƃ��j�R�[�h�W�҂��Q���������A�{�i�I�ȋc�_�ɂ͂���O�ɁAISO/IEC��ꍇ���Z�p�ψ�������ψ���iISO/IEC JTC1/SC2�j�Ń��j�R�[�h�Ƃ̍��̂��ǂ�ǂ�������������Ă��������߂ɁA�����؍��������ψ���͊��������̉\�����c�_����ꂩ��A����ł̋��ʊ����Z�b�g������ɐ��i���ς���Ă������B���j�R�[�h�����p�ӂ��������Z�b�g�Ă͑����̖�肪�������̂ŁA�������p�ӂ���HCC���������\���x�[�X�ɁA�����̃��[�h�̂��Ƃɂł����������̂�CJK���������\�ŁA2��902�������ڂ���BCJK�Ƃ�China�AJapan�AKorea�̗��ł���i���݂͎��f�������F�g�i����������ACJKV�Ƃ����Ă���j�B
�@CJK���������\�ł͕����ɑΉ���������ؑ�̎���E���̂��l���ɕ��L����A�Ή����鎚��E���̂��Ȃ������ꍇ�͋ɂȂ�B[�}6]
���������\�ɂ́A���̕����̌��K�i�ɂ����镄�����L�ڂ���A���K�i�Ƃ̑Ή��W��ISO/IEC 10646�K�i�̈ꕔ�ƂȂ����B��x�A���������\�ɍڂ��Ă��܂��ƁA���{�̏�p�����\����̂悤�ȍ�����������Ă��A���̍��̈ꑶ�ł�ISO/IEC 10646�Ƃ̑Ή��W��ύX�ł��Ȃ��Ȃ邪�A����͕����R�[�h�̂��яd�Ȃ�����ɕs���������Ă������ۓI��ƂɂƂ��Ă͊��}���ׂ����Ƃ������낤�B
�@�����̔z�́w�N�����T�x�̕��я�����̋��菊�Ƃ��A�N�����T�ɂȂ����͓��{�́w�势�a���T�x���Q�Ƃ��A�w�势�a���T�x�Œ��O�ɒu����Ă��鎚�̎��ɑ}�����邱�ƂɂȂ����B�w�势�a���T�x�ɂ��Ȃ����͒����́w����厚�T�x�A����ɂ��Ȃ����͊؍��́w�厚���x���Q�Ƃ���BCJK�����Z�b�g���\�z����ۂɎ��W���ꂽ�f�[�^��Unihan.txt�Ƃ��āA���j�R�[�h�E�R���\�[�V�A���̃T�C�g�Ō��J����Ă���i��10�j�B
�@ISO 10646�̍ŏ��̌��Ă͊��������R�[�h�����̂܂��^���Ă����̂ŁA���������R�[�h�ɂ���ĕ���������������ISO 10646���Ăɕϊ���A���̕����R�[�h�ɂ��ǂ��Ă��A�f�[�^���ς�悤�Ȃ��Ƃ͂Ȃ������B�������A���j�R�[�h������ISO/IEC 10646�ł́A���������̂��߂Ɍ��̕����R�[�h�Ƃ͗��x���قȂ��Ă���A�����ϊ��������Ȃ��ƃf�[�^���ς��Ă��܂��|�ꂪ�������B
�@���Ƃ��A��p��CNS 11643�ł́u���v�Ɓu���v�͓Ɨ��̕����Ƃ��Ă������Ă��邪�A�����̃��j�R�[�h�́u���v�Ɓu���v�����Ă����̂ŁACNS 11643�����j�R�[�h��CNS 11643�Ƃ��������ϊ��������Ȃ��ƁA�u���v���u���v�ɉ����Ă��܂��B
�@���x�̃Y������ɂ��Ă������{��ISO�������̌��I�K�i�œƗ��̕����Ƃ��Ă������Ă��銿���́A�������ׂ��͈͂ł����Ă��A�ʎ��Ƃ��Ă��������Ƃ��Ă��A�������ꂽ�B��������K�i���������Ƃ����i��11�j�B
�@�݊����̖�肩��ʎ����������]�܂��������̒��ɂ́A���K�i���������Ƃ��Ă͂���ɂ��������������B
�@�O�͂łӂꂽ�悤�ɁAKS C 5601�ł́u�O�v�̂悤�ȕ����̓ǂ݂����������A�ǂ݂��ƂƂɏd���o�^���Ă���B�����ϊ��ɂ�镶�������������ɂ͕ʎ��Ƃ��Ă����������Ȃ����A�ꍑ�̌��ꕶ���̓��ꎖ��ɂ����̂Ƃ͂����A�܂���������̊����ɏd�����ĕ������������邱�Ƃɂ͋��������������B
�@�܂��A���{IBM�͎��Ђ̑�^�@�Ƃ̏������̂��߂�JIS�ɒlj�����IBM�g�������̂����A�u��v�̂悤�Ȉّ̎��i�����炪�{���̎��̂����j��Ɨ��̕����Ƃ��Ď��^����悤�A�J�i�_��ʂ��ėv�������B
�����������͌��K�i���������Ɠ���ɂ������킯�ɂ͂����Ȃ������̂ŁA�����̈�iR�]�[���j�Ɍ݊������Ƃ������ʋ���݂��Ď��^�����i��12�j�B
�@���K�i���������Ƃ̈Ⴂ�́A�݊������̎��͓̂��������̒��ɕ�܂���Ă���_�ł���B���Ƃ��AU+9686�͓��{��������{����Ȃ��u���v�����A���̍��̗��ł͖{���́u��v�ƂȂ��Ă���BU+9686�́u��v�Ɓu���v�����Ă���ȏ�AU+F9DC �Ƃ��Ď��^����Ă���IBM�g�������N���́u��v�́A�݊����ێ��̂��߂����ɗp�������O�I�Ȏ��ŁAISO/IEC 10646���ł́u����Ȃ��g�p�֎~�ɋ߂��v�ƈʒu�Â����Ă����B�������A�����ɂ�����ɗ�O�������āA�u���v�A�u���v�Ȃǂ͓��������ɏ����鎚�ƕt�����ŋK�肳�ꂽ�A�g�p���F�߂��Ă����B
�@�Ȃ��A�݊������̗Ꭶ���`�͈�����ŁA�e���������ׂ��Ȃ����L�������Ȃ��Ȃ��Ƃ����_���A���K�i���������Ƃ͈قȂ�B���̎��_�ł͌݊������͗��x�������Ȃ������̂ł���B
�@CNS 11643��1992�N��3�`7�ʂ��lj�����A�����͈͓��ّ̈̎����������^���ꂽ�BCNS�̐V���Ȉّ̎��͓��{���̎��̂Əd�Ȃ���̂����������̂ŁA���K�i���������Ƃ���͖̂����������B�݊������Ƃ��ĂȂ���^�\�Ȃ͂����������A�݊������̒lj��͋�����Ȃ������B�Ƃ��낪�A2000�N�ɂȂ�ƁA�g��A�R�c�̍ŏI�i�K�Ō݊������̈ʒu�Â����傫���ς�A�lj�����������ւ���邱�ƂɂȂ����i���͎Q�Ɓj�B
�@�Ȃ��ABMP�ɂ�6400�����p�̑傫�ȊO���̈悪���邪�A���K�i����������݊������Ƃ��Ď��^����킯�ɂ͂����Ȃ�����I�����R�[�h�ّ̈̎����A�����ɊO���Ƃ��Ĕz�u���邱�ƂɂȂ��Ă����Ƃ�����������i��13�j�B
�@���{�͓��������̌p���I�ȃ����e�i���X�̕ۏ����Ƃ߁A���ۓI�ɏ��F���ꂽ�B�����e�i���X�ɂ�IRG�iIdeographic Rapporter Groupe�A�����A����j�������邱�ƂɂȂ����B
�@������1�����̊����lj����Ă������A���̃X�y�[�X�ɂ̓n���O�������`�i��14�j�����^���邱�ƂɂȂ��Ă��܂����̂ŁA�܂Ƃ܂����Ƃ��Ă̓n���O���̂͂����Ă���6��500���]�̃X�y�[�X�����c���Ă��Ȃ������B������1�����lj��ɌŎ��������A���������̉\������������Ƃ��������őË����͂����A�lj�������1��������6��500���]�Ɉ��k���ꂽ�B���ꂪ��̊g��A�̌��`�ł���B
�@�������A���������͋Z�p�I�ɓ�_�������ɁA����i���m�ɂ́u�����\���L�q�����v�j�̏���ȑg�ݍ��킹�ɂ���āA���ۂɂ͎g��ꂽ���Ƃ̂Ȃ��������ǂ�����ʂɐ��܂ꂩ�˂Ȃ������B�Ƃ����āA����̑g�ݍ��킹�������ɋK�肷��ƁA�������ꎚ�ꎚ���^����̂Ɠ������ƂɂȂ��Ă��܂��A���U�@�̊����g�����Ƃ��������A�Z�p�I�ɂ��K�i�Ƃ��Ă����肷��B���U�@�ł̊����g����S�苭���咣���Ă������{�͊��������������铮�c���o���A���ۓI�ȗ������Ƃ�����B
�@���̍��ɂ͊����ȊO�ɂ������lj��v�����������ł���ABMP�O�֊g�����邱�Ƃ��K�v�Ƃ������ۓI�ȃR���Z���T�X����������Ă����B�������A32�r�b�g��UCS4�Ɉڍs����ɂ͒�R�������A�Ƃ�����ISO/IEC 2022�̂悤�ȕ����ʐ�ւ������i��15�j���Ƃ�̂������Ƃ��������ǂ���̏������B
�@���]�̍�Ƃ��āA���j�R�[�h���ɂ���Ē�Ă��ꂽ�̂��T���Q�[�g�y�A�i�㗝�y�A�j�ƌĂ��g���@�ł���B
�@�T���Q�[�g�y�A�ł́AUCS2��16�r�b�g�������g�݂��킹�邱�Ƃňꕶ��������킷�B�O���̈�̒��O�Ɋg���p�̗̈��݂��AU+D800�`U+DBFE�͈̔͂�1024�̕������1�o�C�g�AU+DC00�`U+DFFF��1024�̕������2�o�C�g�Ƃ���B1024�~1024=104��8476�������e�ł��邪�A�����6��5�玚���p�\��16�r�b�g�̕����ʂ�16�ʕ��ɂ�����ABMP�i��0�ʁj�ɂÂ���1�`16�ʂɌ����Ă�B���̍H�v�ɂ���āAUCS2���̕���������100�����̊g�����\�ɂȂ����킯�ł���i16�r�b�g���������Ȃ̂ŁA�V�X�e���̉����͍ŏ����ł��ށj�B
�@�T���Q�[�g�y�A��ISO�ł�UTF-16�ƌĂ�邪�A�l�b�g���[�N�Ƀf�[�^�𗬂����߂ɍl�Ă��ꂽ����UTF�Ƃ͈Ⴂ�A�����܂�UCS2�̎��^�������𑝂₷���߂֖̕@�ł���BUTF-8�ɕϊ�����ꍇ�́A�T���Q�[�g�y�A�̂܂܂ł͂Ȃ��A��x�AUCS4�̕����ɂ��ǂ��Ă���ϊ�����B
�@�����Ɋւ��ẮA2000�N�ɋ��n���O���̈���g����6582���̊����lj��������Ȃ�ꂽ�i�g��A�j�B�Â���2001�N�AUTF-16�i�T���Q�[�g�y�A�j�Ŏg����悤�ɂȂ�����2�ʁiSupplementary Ideographic Plane�A�⏕�����ʁj�Ɋg��B�Ƃ���4��2711�����lj����ꂽ�B
�@IRG�i�����A����j�ł͊����������̖�������F���钆���̐ϋɓI�Ȏp�����ڗ����A�g��B�̋K�i�[��O���t�͒��������p�ӂ����B�g��B����e���̗Ꭶ���`���L����߁A�����̎��`���f����݂̂ɂȂ����̂́A�����̐ϋɍ�Ɩ��W�ł͂Ȃ����낤�B
�@ISO/IEC 10646�͒a������킸��8�N�ԂŁA�����̍\�z���͂邩�ɒ�����7�����߂����势���Z�b�g�����������ތ��ʂƂȂ����B�ډ��A�g��C�̏������i��ł��邪�A�g��C�͑�2�ʂ̎c��߂�2��2�玚�̊g��C-1�ƁA��3�ʂ��g���g��C-2�̓�i�K�ɂ킯�Ēlj������悤�ł���B�߂������AUCS������10��������̂͊m���ł���B
�@���ۋK�i�ɂȂ����Ƃ͂����Ă��AUCS��16�r�b�g�Ȃ���32�r�b�g��1�o�C�g�Ƃ���V�����\���̕����R�[�h�Ȃ̂ŁA�Ή�����\�t�g�E�F�A���Ȃ��Ȃ������Ȃ������B
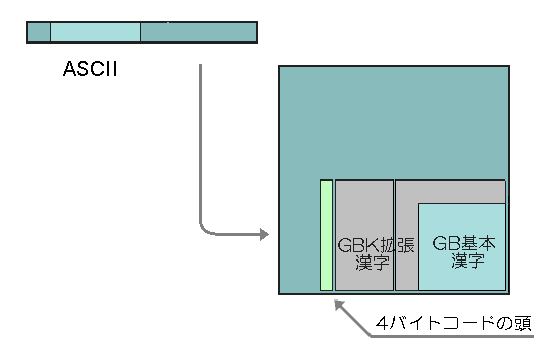
�@������1995�N��GBK�i�g��GB 2312�Ƃ����Ӗ��̒ʏ̂ŁA�����ɂ́u���������g�W�K�́v�j�Ƃ��������R�[�h�̎d�l�\�����B
�@GBK��EUC-CN�̋ɁAGB 2312�����^��UCS�������}�b�s���O���������R�[�h�ŁAGB 2312�̏�ʌ݊��ɂȂ��Ă���B�t�H���g��GBK�Ή��̂��̂Ɍ�������������A�]���̃V�X�e����UCS���������ׂĎg����悤�ɂȂ����̂ŁA�L�����y�����i��p��Big5+�A�؍���HCN���ގ��̊g���ł���j�B
�@�������A2000�N��UCS�Ɋg��A���lj������ƁA��肪�N�����BGBK�̂��߂�EUC-CN�̋͂قږ��܂��Ă���A6�玚����g��A�������X�y�[�X���Ȃ������̂ł���B
�@UCS�����͊g��B�A�g��C�Ƒ��₪�\�肳��Ă����̂ŁA������2000�N��GB 18030�Ƃ����V���ȕ����R�[�h�����ƕW���Ƃ����BGB 18030��GBK�̂킸���Ɏc�����ԍ���擪�o�C�g�Ƃ���4�o�C�g�R�[�h���\��������̂ŁAGB 2312�����GBK�̏�ʌ݊��ƂȂ��Ă���B[�}8]GB 18030�͐V���ȕ����R�[�h�Ƃ������́AASCII�݊���UTF-8�ɑR������̂ƍl���������悳�����ł���B
|
| 1st�o�C�g | 2nd�o�C�g | 3rd�o�C�g | 4th�o�C�g | |||
|---|---|---|---|---|---|---|
| 1�o�C�g�̈� | 94�� | 33-126 | �@ | �@ | �@ | ASCII�݊� |
| 2�o�C�g�̈� | 23,940�� | 129- 254 | 64-126 128-254 | �@ | �@ | GBK�݊� |
| 4�o�C�g�̈� | 1,587,600�� | 129- 254 | 48-57 | 129-254 | 48-57 | �@ |
�@���{�̏ꍇ�A�f�t�@�N�g�W�������Ă����V�t�gJIS�ɂ�4�玚�قǂ̋����Ȃ������B�������AWindows�O���̂悤�Ƀx���_�[���̈ꕔ���V�X�e���O���Ɏg���Ă������߂ɁAGBK�̂悤�Ȋg���͕s�\�ŁA���j�R�[�h�����ɂ�鐳�U�@�̊g����I�Ԃ����Ȃ������B
�@���j�R�[�h�œ��������������Ȃ��Ă��鐻�i�ł��AOS�ɂ���Ă͓��ڃt�H���g�̎��^���ɂ��Ȃ�̈ٓ�������B
�@OS�̕W���t�H���g�ɂ͂����Ă��Ȃ������́A������UCS�����ł���ɂ�������炸�A����OS�ł͕\�����ꂸ�A���{��������̏�Q�ƂȂ��Ă���B�������������͓���OS�̕W���t�H���g�ɂ͂����Ă��Ȃ������ŁAISO 10646�ɂ����Ă͍��ۓI�ȍ��ӂɂ��ƂÂ������ʒu�����������Ă���ȏ�A�@��ˑ������Ƃ͂͂�����قȂ�BWindows����Macintosh�ɈڐA�����\�t�g�E�F�A��Windows�Ɠ����t�H���g��������Ƃ����悤�ȗ͂܂����̉����@�����邪�A���̃\�t�g�E�F�A�̂͂����Ă��Ȃ��@�B�ł͏͕ς�Ȃ��B
�@JIS�ł͂��̖����ǂ��l���Ă���̂��낤���H�@ISO/IEC 10646-1�������K�i������JIS X 0221-1:2001�̉���́u3.5.3 J���̎��`�̗L���v�ɂ͎��̂悤�ɏ�����Ă���B
�@���̋K�i�̓��������̏ڍו����\��J���Ɏ��`��������Ă��Ȃ������������ɂ��āA�g���̕����͉䂪���ł͎g�p�ł��Ȃ��B�h�A�g���̕���������̕\�L�ɗp���邱�Ƃ͌��ł���B�h�ȂǂƂ�����߂����邱�Ƃ����邪�A�����͌��ł���B���̋K�i��J���ɑΉ����鎚�`�������Ă��Ȃ�����̕������������A�䂪���̍����̗��p�ŁA����̕\�L�̂��߂ɗp���邱�Ƃ��A���̋K�i�͋֎~���Ă��Ȃ��BJ���Ɏ��`�������Ă��Ȃ����������̒��ɂ́A�Ⴆ�A�����̒����ȑ̎��̂悤�ɁA�䂪���ō���̕\�L�ɗp���邱�Ƃ��l���ɂ������̂��܂܂�Ă���B�������A�K�i�̏�ł́A�i������ł����Ă��A���̕�����p���邱�Ƃ��K�ł���Ύ��R�Ɏg���Ă悢�B
�@����w��s�W���ƂȂ�u���{�R�A�����v�̂悤�Ȏ��݂����邪�A���{��\�L���ɕK�v�ȋ��ʕ������p�[�g���[���m�肷�邱�Ƃ��ً}�ɕK�v���낤�B�Ȃ��A�ߑ�̕��w��i�̓d�q���ɂ��ẮA�Ǝ���UCS�̂������Ŏg����悤�ɂȂ����̂ɁA�ނ��댩���ꂽ���̂�����N�����T�̂�J���ɂȂ����߂ɁA�ˑR�Ƃ��Ďg���Ȃ��Ƃ�����肪����i�Y������̂͐琔�S�������A���������t�H���g�ł́uFDPC�lj������v�Ƃ��āA���łɃt�H���g������Ă���j�B
Copyright 2004 Kato Koiti